-
[DBMS] Buffer Management개발 이야기/DB(데이터베이스) 2024. 11. 23. 20:54
본 내용은 한양대학교 차제혁 교수님의 DBMS 수업을 기반으로 작성하였습니다.
추가 참조는 아래와 같습니다.
CS186Berkeley
https://coldyun.tistory.com/18
https://dongwooklee96.github.io/post/2021/12/29/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EB%B2%84%ED%8D%BC%EB%A7%A4%EB%8B%88%EC%A0%80buffer-manager%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80.html

앞서 말한 Disk space management의 윗단에 존재하는 Buffer management에 관해 알아보자. Buffer는 memory illusion을 만들어주는 매우 주요한 장치이다. Disk의 경우 그 속도가 매우 느리기 때문에 Buffer를 통해 File을 다루는 것이 일반적이다.

Buffer management는 RAM과 Disk space mangement 사이 Disk I/O의 속도가 느리기에 이런 오버헨드를 방지하기 위해 Buffer를 통해 이를 해결하고자 하는 것이다. 그럼으로 Buffer management는 아래의 2가지 역할을 한다.
1. Cache 역할
최근 접근된 페이지들을 메모리(프레임)에 담아두고, 해당 페이지가 다시 접근되면 Disk까지 갈 필요 없이 버퍼 프레임에서 바로 꺼내줄 수 있도록 합니다. 이때 프레임은 버버에서 다루는 페이지와 동일한 의미로 생각하면 된다.프레임: 프레임은 버퍼를 구성하는 단위이다.
1. 각 프레임의 크기는 디스크 페이지의 크기와 같다
2. 프레임은 디스크 페이지의 캐시를 포함가능하다
3. 모든 프레임은 RAM에 저장된다2. Write Buffering
특정 페이지에 새로운 데이터를 Write할 때, 실제 디스크에까지 저장은 실시간으로 이루어지지 않는다. 이는 위에서 말한것처럼 I/O 오버헤드를 최소화하기 위해서이다. 버퍼는 이런 memory illusion을 유저에게 구현하며 실제 Disk에 저장하는 작업은 따로 수행g한다.
하지만 이렇게 Write를 버퍼에만 저장해놓고 디스크에는 이후에 저장하도록 하면, 버퍼와 디스크에 저장된 페이지 내용에 차이가 생길 수 있는 문제가 있는데 이를 Dirty page라고 한다.결국 버퍼 매니지먼트는 캐싱과 페이지 교체를 통해 I/O 비용을 최소화 하는 것이 목적이다.
프레임: 프레임은 버퍼를 구성하는 단위이다.
1. 각 프레임의 크기는 디스크 페이지의 크기와 같다
2. 프레임은 디스크 페이지의 캐시를 포함가능하다
3. 모든 프레임은 RAM에 저장추가적으로 버퍼에서 찾고자 하는 페이지가 존재한다면 Hit / 존재하지 않는다면 Miss라고 말한다. Miss라면 디스크에 접근하여 해당 페이지를 읽어야하는데 이때 발생하는 비용을 Miss penalty라고 한다.
Dirty page Handling
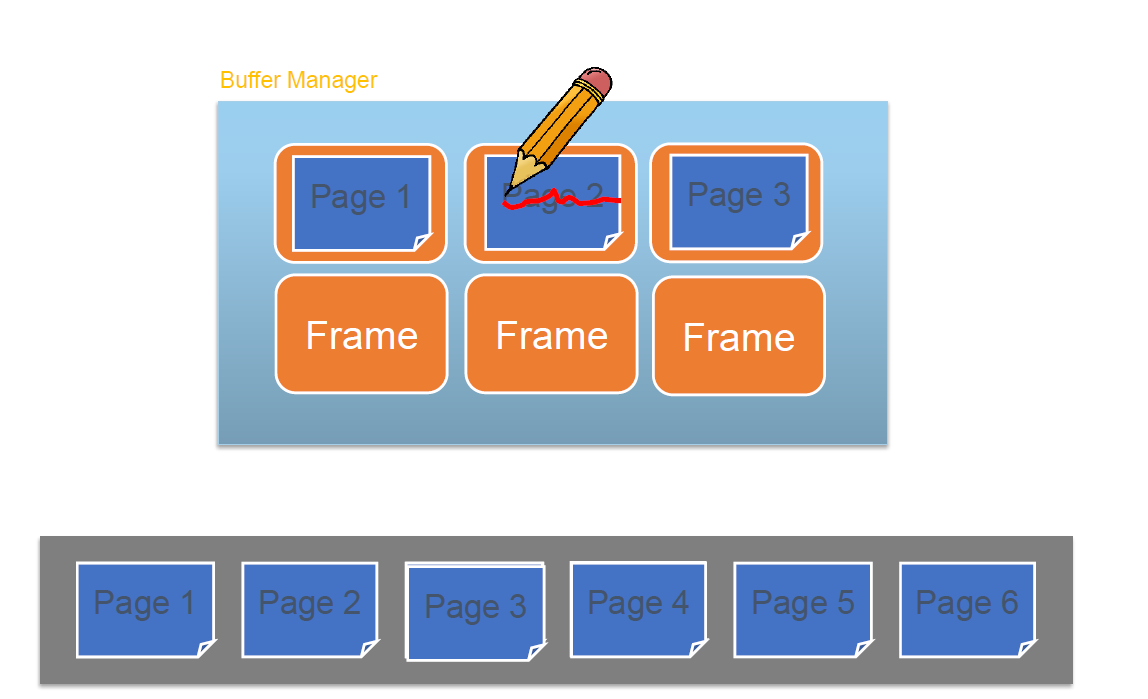
Dirty page란 메모리에 올라온 데이터와 디스크에 있는 데이터의 내용이 다른 페이지를 의미한다. 더티페이지를 관리할 때 중요한 것은 2가지로 1. 버퍼 매니저가 더티 페이지를 어떻게 찾아낼 수 있는가 2. 더티페이지를 어떻게 처리할 것인가, 즉 disk manager에 어떻게 반영할 것인가. 이다.
이는 데이터의 동시성과 리커버리 관점에서 중요하다(데이터가 유실되면 안된다).
버퍼 매니저에서 프레임은 테이블처럼 관리되며, 페이지 아이디와 Dirty flag, pin count를 통해 관리된다.
이때 Dirty 플래그는 Dirty page를 관리하기 위해 사용되며 pin count는 현재 사용되고 있는지를 확인하는데 사용된다.
Buffer Manager State

Buffer mangaer에는 Buffer에 올라온 페이지들을 저장하는 Frame이 존재한다고 밝힌 적이 있다. 헤당 Frame에서는 위와 같은 meta data 또한 함께 관리해야한다.
Meta data에는 Page_id, Dirty bit, pin count 등이 존재한다.
Page id는 해당 page를 구분하기 위한 index이다.
Dirty bit는 페이지의 데이터가 변경되었는지 확인하는 속성
pin count는 해당 페이지를 현재 사용하고 있는 작업의 수를 측정
When Page request...
page가 요청되면 아래의 2가지 케이스로 나누어진다.
1. If requested page가 not in pool(if request is miss)
a) un-pinned(pin count = 0)인 frame을 선택한다(제거하기 위해)
b) 선택된 프레임이 dirty라면 해당 페이지를 disk에 기록하고 clean으로 기록한다.
c) 선택한 프레임에 requested page를 읽는다.
2. If page in pool: 바로 address 반환하고 pin한다
이 과정에서 request가 예측 가능한 경우 page가 pre-fatched 될 수 있다.
After Requestor Finshes
요청자가 작업을 마친 이후
1. Page requester는
- 페이지가 수정되었을 경우, dirty bit를 설정한다.
- 페이지의 고정을 unpinned 해야 한다(가능한 빠르게)
- pin의 경우 메모리 공간의 효율성을 위해 필요하며 이 과정이 느리게 이루어질 경우 다른 요청이 메로리르 활용하지 못해 시스템 성능이 저하될 수 있다.
2. Buffer pool내의 페이지는 여러번 요청될 수 있음
- pin count가 현재 몇개의 요청에 의해 사용 중인지 추적하는 값
- pin count가 사용되고 이때 pin_count ++가 수행된다 /작업이 끝나는 경우 pin_count--
- page는 pin_count == 0인 경우, 즉 고정해제인 경우 replacement 후보로 선정된다
3. Recovery
dirty bit처리(Write Ahead logging 및 비정상 작동 처리) 및 동시정 제어(Concurrency control, 동일한 페이지 관해 원자성 지키기)에서 추가적인 I/O가 발생할 수 있음.
Page Replacement
Page replacement는 위에서 페이지를 교체할 때 선택하는 정책으로 대표적으로 아래의 3가지가 존재한다.
- LRU(Least Recently Used): 가장 오랫동안 사용되지 않은 페이지 교체.
- MRU(Most Recently Used): 가장 최근에 사용된 페이지 교체.
- Clock: LRU를 효율적으로 구현한 방식으로, 참조 비트를 사용해 교체 대상 결정.
이는 버퍼의 용량이 제한되어있기에 hit ratio를 올리기 위해 사용된다. 그럼 사용이 잘 되지 않는 페이지를 어떻게 알아낼 수 있을까?
LRU(Least Recently used)
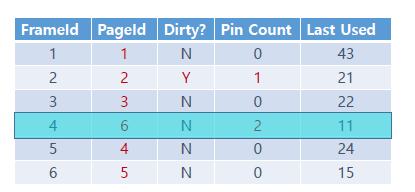
LRU 방식은 문자 그대로 마지막으로 사용한 시점이 가장 오래된 페이지를 지우는 것이다. 위의 frame의 metadata를 보면 Last used 시점이 가장 오래된(숫자가 작은) 4를 선택하는 것을 볼 수 있다.
이는 가까운 시간내에 같은 페이지를 다시 접근하는 경우가 많은 temporal locality 상황에서 사용하기 적합하다(혹은 poplular page가 존재하는 전략)
다만, time stamp에서 min을 찾아야하기에 costly 할 수 있다. 그럼으로 Clock LRU방법을 생각할 수 있다.
Clock
Clock 알고리즘은 LRU의 동작을 근사한 알고리즘이다. 이는 LRU방법이 costly하기 때문에 필요하다.
Clock 알고리즘은 정확한 시간을 계산하는 대신 대략적으로 LRU를 처리하는데 그 방법은 다음과 같다
우선 Clock은 시계바늘로 다음에 교체할 페이지를 가리키고 있다. 또한 각 프레임의 reference bits는 가장 최근에 참조된 페이지를 말한다.

위와 같은 상태에서 page 7을 읽은라는 요청이 생겼을 때 어떻게 작동해야하는지 보자.
1. page 7을 찾는 경우 우선 핀이 없는 페이지를 시계바늘 순서대로 찾아가다가

핀이 없는 페이지 3을 가리킬 때 ref_bit가 체크되어있다면 체크를 해제한다(Clock이 한바퀴 돌 동안 불러온적이 있는 것임으로 교체하지 않고 일단 0으로 변경)
이후 page4의 경우 ref_bit가 -이고 unpinned되어있는 페이지기에 해당 페이지를 교체한다.


실 구현에서는 pointer를 통해 현재 검사 중인 프레임을 가리킨다.
이는 페이지 교체를 수행하기 위해 각 프레임의 상태를 확인하기 위함이다.


MRU(Most Recently Used)
What about repeated scans of big files? 만일 아래의 그림과 같이 연속적으로 페이지에 접근하는 상황이라고 가정해보자. 이 경우 Miss가 계속 일어나며 hit가 0일 것이다. Sequential Flooding이라고 불리는 이 상황은 Repeated scan 상황에서 프레임의 용량보자 자주 접근되는 데이터의 set이 클 때 LRU에 의해 계속 miss가 나는 최악의 경우이다.

이런 경우 MRU방법이 효과적이다.
MRU의 경우 가장 최근에 사용한 페이지를 지우는 전략이다. 이는 해당 페이지가 최근에 사용되었으니 조만간은 사용되지 않을 것이라는 생각이 반영된 것이다. 위의 케이스에서는 버퍼매니저에 1 ~ 6까지 7 페이지를 읽어야 할 때 6을 제거하고 7을 넣는 것이다. 그려면 다시 1 ~ 5까지의 데이터를 읽을 때는 페이지 교체를 하지 않아도 되므로 연속적인 데이터를 읽을 때 페이지 교체가 덜 일어날 것이다. 즉 Spacial locality에서 효율적으로 동작한다.
PreFetch
위처럼 LRU는 연속된 페이지가 연속적으로 요청되는 spacial locality 상황에서 문제가 있었기에 이에 대한 Optimization을 위해 Prefetch 라는 방법을 추가적으로 사용할 수 있다.
Prefetch는 한 페이지가 요청되었을 때, Disk Space Manager에게 이후 연속된 몇개의 페이지도 추가적으로 한꺼번에 가져오는 방법이다. 이도 추가적으로 알아두자+) DBMS vs OS Buffer Cache
OS에 있는 Buffer와 DBMS의 Buffer는 무슨 차이인가?
운영체제는 File system을 통해 디스크의 데이터를 관리하며 버퍼와 페이지 캐싱을 수행하는데 DBMS는 이와 별도로 Buffer managmenent를 사용하는 이유는 아래와 같다.
1. 이식성(portability)
서로 다른 파일시스템은 각기 다른 방식으로 동작(NTFS(Windows)와 ext4(Linux)는 파일 관리와 캐싱 방식이 다름)하는데 DBMS는 다양한 플렛폼에서 동일한 동작을 보장해야한다.
2. Limitation of OS: Force Pages to Disk
DBMS는 데이터를 강제로 디스크에 쓰기(write)를 수행해야 할 때가 있다(예: 트랜잭션이 완료되었을 때 변경된 데이터를 디스크에 저장). OS는 일반적으로 버퍼 캐시를 통해 디스크 쓰기를 지연시키지만, DBMS는 복구(recovery)를 위해 즉각적인 디스크 기록이 필요하기에 그 차이가 존재한다.
3.DBMS can predict its own page reference patterns
DBMS는 자체적으로 페이지 참조 패턴을 예측할 수 있다. 예를 들어 B+-트리의 리프 노드를 스캔할 때, 연속된 데이터 접근이 발생하는 케이스가 있을 것이다.
이러한 패턴을 알고 있는 DBMS는 적절한 **페이지 교체 정책(page replacement policy)**과 **사전 읽기(prefetching)**를 적용하여 성능을 최적화 가능하다.하지만 OS는 DBMS의 내부 구조와 패턴을 알지 못하므로 이러한 최적화가 어렵다.
'개발 이야기 > DB(데이터베이스)' 카테고리의 다른 글
[DBMS] Heap File & Sorted File (1) 2024.11.24 [DBMS] Data Representations: Files, Pages,Records (0) 2024.11.24 [DBMS] Disk and Disk Space Management (0) 2024.11.22 [DB] SQL2: SELECT와 Relational Algebra 중심으로(조회) (2) 2024.10.19 [DBMS] SQL1 - Schema definition & Update & Insert 위주로 (0) 2024.10.18