-
[DBMS] Data Representations: Files, Pages,Records개발 이야기/DB(데이터베이스) 2024. 11. 24. 16:58
본 내용은 한양대학교 차제혁 교수님의 DBMS 수업을 기반으로 작성하였습니다.
추가 참고 자료는 https://dongwooklee96.github.io/post/2021/12/16/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%ED%8E%98%EC%9D%B4%EC%A7%80-%EB%B0%8F-%EB%A0%88%EC%BD%94%EB%93%9C-%EA%B5%AC%EC%A1%B0.html
https://velog.io/@impala/DB-Data-Storage-Structure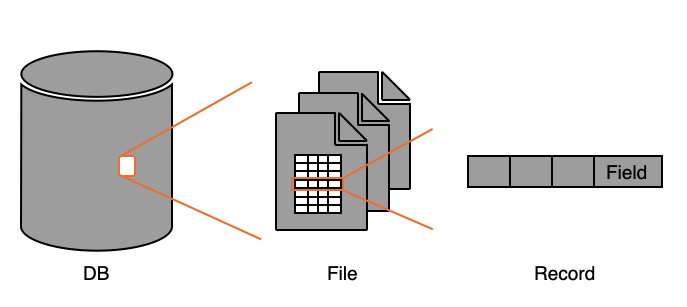
출처: https://velog.io/@impala/DB-Data-Storage-Structure 데이터베이스는 저장소에 저장된 File의 모음이고
File은 Record들의 집합(Sequence)이고, Record는 각 Field로 구성되어 있다(Record를 tuple로 field를 각 attribute라고 생각하자)
다만 앞장에서 다루었듯, 우리는 page 단위로 디스크에서 데이터를 읽어왔다. 그렇다면 page와 File은 어떻게 연결되는 것일까?
File은 locigal 한 단위이고, Page는 여러 Record를 물리적으로 가지고 있는 단위라고 생각하면 된다. 실제로 DBMS는 memory 단위, 즉 더 higher level에서 데이터를 다룬다. 이 관계를 정의하기 위해 Blocking factor가 존재한다(한 페이지/블록 안에 저장되는 레코드의 수를 정의).
Database Files
File은 page의 집합으로 정의된다, 각 페이지는 record의 집합을 포함하고 있다.

파일은 삽입, 삭제, 수정 작업을 지원하며 특정 레코드를 레코드 ID로 검색하거나 전체 레코드를 순회할 수 있다.
File의 구조 유형은 아래와 같다.
- Heap Files (Unordered):
- 레코드가 순서 없이 페이지에 저장.
- 레코드 삽입 시 페이지와 빈 공간 관리 필요.
- heap 자료구조와 다르다!
- 파일이 줄어/늘어나면 페이지 할당이 (de)allocated된다
- Heap file 자체는 조건 기반 검색 시 파일의 순차 스캔만 가능 -> Index가 필요한 이유
- Clustered Files:
- 비슷한 레코드가 물리적으로 가까운 페이지에 저장.
- 연관된 레코드들을 모아서 관리하기 때문에 JOIN쿼리에 유리
- 단일 테이블을 조회하는 쿼리에는 공간적으로 비효율적
- Sorted Files:
- 레코드가 정렬된 순서로 저장.
- Seqeuntial이라고도 함
- Index Files:
- B+ 트리 또는 해싱을 통해 레코드에 빠르게 접근.
- B+트리의 leaf node에 레코드를 저장하는 방식으로, INSERT와 DELETE연산에서도 순서가 보장
- 해시함수에 search-key를 넣어 계산한 값을 통해 레코드가 어느 블록에 위치하는지 찾을 수 있음
각 방법에 관한 것은 차후 자세히 다루어보려고 한다.
Page

page는 페이지 헤더가 있는데 페이지에 대한 메타정보를 담고 있다. 레코드의 숫자, 남은 공간, 다음 또는 이전 페이지에 대한 포인터, 비트맵, 그리고 슬롯 테이블을 가지고 있다.
페이지 layout을 설정하는데는 2가지 관점이 있는데
- Record length: Fixed or Variable - Record의 길이는 변하는가?
- Page Paking(packed or unpacked) - Record간 빈 공간이 존재하는가?
페이지에서 레코드는 레코드 아이디를 통해 찾을 수 있으며 레코드 ID:({Page Id, Offset)로 저장된다.
이 2가지 관점 * 2가지 경우에 관한 Case에서 Search, Insert Delete하는 경우를 확인해보자.
우선 Disk Adderess는 linear하나 보다 보기 쉽게 하기 위해 직사각형으로 wrap out했음을 유의히자.


Case1: Fixed length & Packed page layout

Case 1구조인 경우
ADD: 레코드를 추가할 때 빈공간을 찾기 매우 쉽다. 우선 페이지 헤더로 가서 레코드의 개수를 확인한 뒤 마지막 레코드로 가서 레코드를 추가하면 된다.
Delete: Delete의 경우 고려해야할 상황이 바로 삭제되고 생긴 빈 공간의 처리이다. 이를 없애기 위해 다른 레코드를 당겨야한다.
Page의 레코드가 변경되는 경우 레코드의 아이디가 순차적으로 변경되어야하기에 연산이 늘어난다.
Case2: Fixed length & UnPacked page layout

구조의 경우 페이지 해더에 비트맵 정보가 포함된다. 이 비트맵 정보를 참조해서 레코드가 비어있는지 아니면 비어있지 않은지 확인할 수 있다.
ADD: 데이터를 추가할 경우에는 페이지 헤더에서 비어있는 레코드를 확인할 수 있는 비트맵을 참고하여 가장 먼저 비어있는 페이지를 데이터를 추가하면 된다.
Delete: 삭제하는 경우에는 그냥 간단하게 비트맵에 해당 레코드 위치의 비트를 삭제되었다고 바꾸면 된다. 언패킹 구조의 경우에 추가 및 삭제가 비트 연산을 통해서 이루어지므로, 매우 빠르다(빈공간 고려 필요 없음)
고정 길이 레코드 방식에서는 모든 레코드의 길이가 같고, 순서대로 저장되어있기에 레코드의 번호만 알면 레코드의 길이 * 번호로 원하는 레코드에 쉽게 접근이 가능했다. 하지만, 가변길이인 경우에는 각 레코드의 길이가 다르기 때문에 새로운 방법이 필요하고, 대다수의 DBMS에서는 Slotted Page Structure를 채택하여 사용한다.
Case 3: Variable Length & Packed -> Slotted Page Structure
slote directory는 다음과 같이 구성된다.
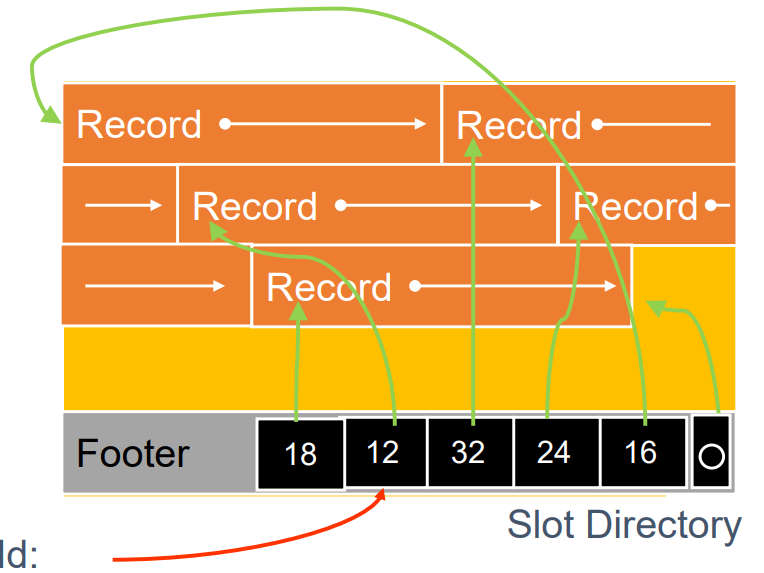
페이지 맨 아래 부분에 슬롯 디렉터리를 가진다. 이를 Footer라고 하며, 이 Footer를 때서 보면

Footer의 경우 free space를 point하는 공간이 가장 마지막을 위치해있다
이후 길이 + pointer 기록하는 공간이 존재한다. 이때 이는 reverse order로 기록된다. 즉, Free space에서 가장 가까운 부분부터 역순으로 기록된다.
Add: 새로운 레코드를 더하는 것은 빈 슬롯을 찾아서 거기에 새로 추가될 레코드의 주소를 가리키면 된다
Delete: 슬롯에서 해당 레코드를 가리키고 있는 슬록을 지우면 된다.
빈공간이 없도록 유지하기 위해 레코드에 변경이 발생하면 레코드의 위치를 조정하여 빈 공간을 Free space로 이동하고 이를 업데이트한다. 다만, 레코드가 업데이트 될 때마다 정리를 해주는 방식과 실제 단편화 때문에 데이터를 넣기 힘들 때 정리를 하는 방식 중 보통 후자를 사용한다고 한다.
또한, 인덱스와 같이 외부에서 레코드를 가리키는 포인터는 레코드의 위치를 가리키지 안고 슬롯의 위치를 가리킨다.
슬롯은 고정된 길이를 가지고, 고정된 위치에 있지만, 레코드는 변경이 발생되면 그 위치가 조정될 수 있기 때문이며 이를 Indirect Access라고 한다.
Record Layout
레코드에서는 타입을 구분하지 않는다, 이는 모두 테이블에 대한 정보에 포함되고 이는 시스템 카탈로그에 기록된다.
Fixed length
Fixed length, 즉 고정길이 레코드의 경우 각 파일의 레코드의 크기가 모두 같은 구조로 i번째 레코드의 시작 주소는 레코드의 크기 * (i-1)로 매우 쉽게 구해진다.
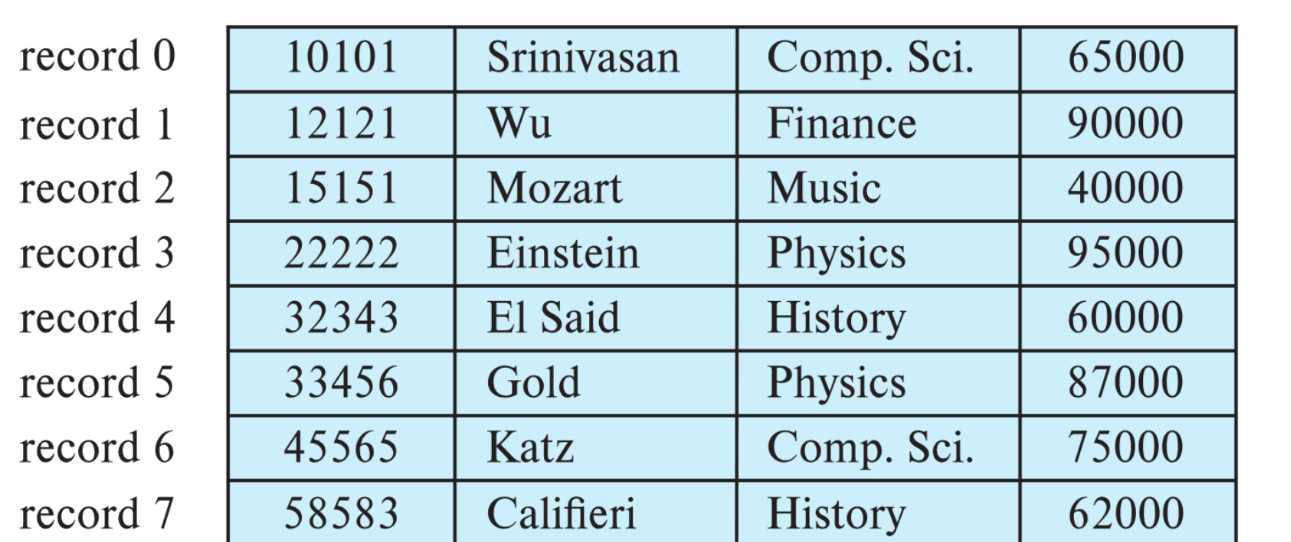
위의 그림과 같이 레코드의 크기가 모두 동일한 케이스이다. 레코드의 크기가 같기 때문에 읽는 것은 매우 간단하다.
Variable length
고정길이 레코드방식으로 데이터를 저장하는 경우 한 파일에 하나의 자료형밖에 저장할 수 없고, 모든 필드가 고정된 길이를 가지기 때문에 유연성이 떨어진다. 이런 단점을 해소하고자 가변길이 레코드 방식이 등장하게 되었다.
가변길이 레코드 방식에서는 하나의 파일에 여러 자료형이 저장될 수 있고, 하나 이상의 필드에 varchar와 같은 가변길이 자료형을 저장할 수 있다. 다만 가변 길이이기 때문에 각 필드를 어떻게 구분해야할지에 관한 고민이 생기게 된다. 간단히 구분자를 넣어줄 수도 있지만, 이는 별도의 낭비되는 메모리의 발생을 초래한다.
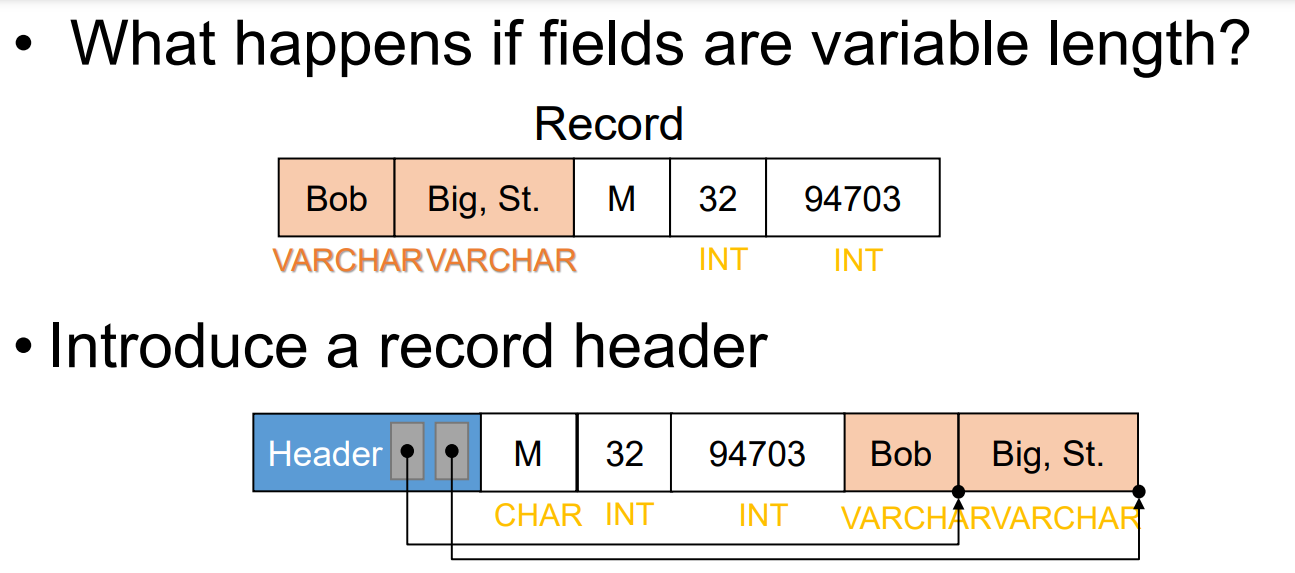
결론은 위의 그림에서와 같이 헤더를 따로 생성하고 각 헤더에서 각 필드의 마지막 위치를 가리킨다. 또한 가변길이 필드는 길이가 변해야하기 때문에 고정길이 필드가 앞에 먼저 오게 되고, 이후에 가변 길이 필드가 저장된다.
'개발 이야기 > DB(데이터베이스)' 카테고리의 다른 글
[DBMS] Index & B+ Tree (0) 2024.11.25 [DBMS] Heap File & Sorted File (1) 2024.11.24 [DBMS] Buffer Management (2) 2024.11.23 [DBMS] Disk and Disk Space Management (0) 2024.11.22 [DB] SQL2: SELECT와 Relational Algebra 중심으로(조회) (2) 2024.10.19 - Heap Files (Unordered):