-
[DBMS] Hash Index개발 이야기/DB(데이터베이스) 2024. 12. 19. 19:15
Hash index란 앞서 말한 Index를 구현하기 위해 Hash 자료구조를 사용하는 방법을 의미한다.
앞서도 느꼈지만 자료구조...를 잘 모르면 DBMS 내용들을 이해하는데 뒷부분으로 갈수록 꽤나 힘이 든다.
그럼으로 Hash 자료구조에 관해 우선 간단히 정리하고 Hash Index에 관해 살펴보자.
Hash
Hash는 Hash함수를 이용해서 얻는 해시값을 이용하는 자료구조를 말한다.
데이터의 Key 값을 해시함수를 통해 간단한 값으로 변환하고 이 변환된 Hash를 배열의 인덱스로 활용하는 방법이다.
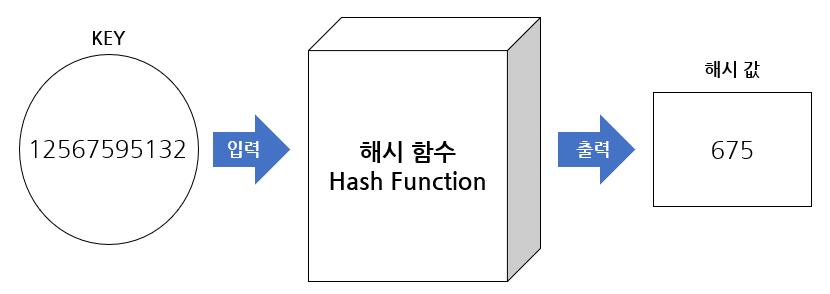
Hash 함수
Hash 함수는 입력된 키를 특정 규칙에 따라 고정된 크기의 해시값으로 변환하는 함수로, 그 특징은 역 변환이 매우 어렵다는 것이다(이는 대다수의 특징이긴 하나 반환을 간단한 규칙으로 만들 수 도 있다고 한다)
Hash Table
해시 table은 Key와 value를 함께 저장해둔 데이터 구조이다. 이는 데이턱가 행과 열로 구성된 표에 저장되는 것과 유사하며, 위티는 무작위로 지정되기에 중간에 여유공간이 발생할 수도 있다.

출처: https://kang-james.tistory.com/entry/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%95%B4%EC%8B%9CHASH-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0 Hashing
해싱은 해시 함수에서 해시를 출력하고 해시 테이블에 저장하는 과정까지의 행위를 말하며 아래의 그림과 같이 표현될 수 있다.

이 때 bucket은 하나의 인덱스 위치를 나타내는 단위로, 함수에 의해 데이터가 매핑되는 파일의 한 구역을 의미한다. 하나 이상의 데이터를 저장할 수 있다.
Slot은 한개의 레코드를 저장 가능한 공간을 의미한다. 보통 한 슬롯은 하나의 데이터 항목을 저장할 수 있다.
Static Hashing(정적 해싱)

Static Hashing은 primarty page의 크기가 고정된 형태, 즉, 버킷의 수가 고정되어있다.
초기 키값에 대해 h(key) mod M을 계산하여 데이터를 저장할 버킷을 결정한다(나머지 연산). 이때 M은 버킷의 총 개수이다.
각 버킷은 고정된 크기를 가지며 넘치는 데이터는 Overflow page에 저장된다.
구조와 구현이 단순하나, 데이터가 증가하면 오버플로 체인이 길어져 검색 성능이 저하되고, 데이터를 분포시키는 해시함수를 잘 설계해야 이를 피할 수 있다.
버킷이 넘치는 현상을 Bucket Overflow라고 한다. Bucket의 enty가 가득한 상황에서 해당 버킷에 엔트리가 추가되는 경우를 말하며 Overflow bucket 혹은 page는 아래와 같이 linked list 형태로 만들 수 있다. 이를 Overflow chaining 혹은 Closed Addressing이라고 한다.

Dynamic Hashing
버킷의 수를 동적으로 바꿔가며 사용하는 Hashing을 Dynamic hashing이라고 하며 이는 extendable hashing과 linear hashing으로 대표된다. 앞서 살펴보았듯이 Satic hashing의 경우 데이터베이스의 효율이 떨어질 수 있는 많은 상황이 존재하기에 이를 해결하기 위해 나왔다.
Extendible Hashing

데이터가 증가함에 따라 동적으로 버킷의 수를 확장하는 방법이다. 이는 다시말해 버킷을 디렉토리 구조로 구성하는 방법을 말한다. 데이터베이스에 레코드의 수가 많아지면 디렉토리 번호를 1bit 추가하여 두배로 늘리고, 오버플로우가 발생한 디렉토리에만 버킷을 추가한다.
각 버킷은 **로컬 깊이(Local Depth)**와 **글로벌 깊이(Global Depth)**로 관리된다.
- 로컬 깊이: 버킷이 사용하는 해시 비트의 개수.
- 글로벌 깊이: 디렉토리 전체가 사용하는 해시 비트의 개수
오버플로 체인을 효과적으로 방지하는 방법으로 디렉토리가 메모리에 적합할 경우 대부분의 검색은 한 번의 디스크 접근으로 해결가능한 장점이 있으나, 디렉토리가 켜질 경우 메모리 사용량이 증가하고, 데이터 분포가 편향될 경우 비효율적이다.
3. Linear Hashing

Extendible Hashing과 달리 디렉토리를 사용하지 않고 해시 함수 자체를 확장하는 방법으로 해시 함수 h0, h1, h2, ...을 순차적으로 사용하여 버킷을 관리하며, 특정 조건이 충족되면 버킷을 분할한다. 예를 들어 초기에 해시함수로 mod N을 사용하다가 데이터베이스에 레코드가 많아지면 해시함수에 mod 2N을 추가하여 0 ~ N-1번 버킷은 mod N으로 관리하고 N ~ 2N-1번 버킷은 mod 2N으로 관리하는 방법이다. 분할은 라운드 로빈(Round Robin) 방식으로 진행된다.
디렉토리를 사용하지 않아 메모리 오버헤드가 낮고, Extendible hashing과 달리 데이터의 분포가 skewed된 경우에도 비교적 효율적으로 동작한다. 하디만 Extendible Hashing에 비해 공간 효율성이 낮을 수 있다.
정리하면
Equality Search가 중심이라면 Hash Index는 빠른 성능을 제공하지만, Range Query는 지원하지 못한다.
Static Hashing은 단순성과 초기 소규모 데이터에 적합하고, Extendible Hashing은 큰 데이터셋에서 효율적이며. Linear Hashing은 메모리 사용이 중요한 환경에서 유리하다로 정리할 수 있다.
'개발 이야기 > DB(데이터베이스)' 카테고리의 다른 글
[DBMS] Index 2(정렬과 저장 Clustering 등) (1) 2024.12.19 [DBMS] Index & B+ Tree (0) 2024.11.25 [DBMS] Heap File & Sorted File (1) 2024.11.24 [DBMS] Data Representations: Files, Pages,Records (0) 2024.11.24 [DBMS] Buffer Management (0) 2024.11.23