-
[DBMS] Index 2(정렬과 저장 Clustering 등)개발 이야기/DB(데이터베이스) 2024. 12. 19. 17:26
본 내용은 한양대학교 차제혁 교수님의 DBMS 강의자료와 https://dongwooklee96.github.io/post/2021/12/25/%EC%9D%B8%EB%8D%B1%EC%8A%A4-index-%EC%A0%95%EB%A6%AC-2.html 님의 자료를 바탕으로 작성하였습니다.
원자료들은 CS186Berkeley 자료입니다.General Index File Properties
Basic Selection:
- 동등 조회 (=)
- 범위 조회 (<, >, <=, >=, BETWEEEN)
- B+TREE 인덱스는 위의 두개의 연산을 모두 지원하지만, 해시 인덱스는 오직 동등 연산만 지원
More Exotic Selections: 다양한 데이터 종류를 처리하기 위한 많은 종류의 인덱스가 종류한다. (R-TREE, KD-TREE, GiST)
Range search와 정렬
Search key는 테이블 내의 각 레코드를 식별하거나 검색하기 위해 사용되는 하나 이상의 속성을 의미한다. 단일키 또는 복합키를 사용가능하며 복합 키는 다수의 속성으로 구성되어있다.
인덱스라고도 표현가능한데, 이때 B+ Tree와 같이 정렬된 인덱스는 키를 기준으로 사전적 순서를 지킨다.
복합 인덱스의 경우 (k1, k2)로 이루어진 경우에는 (k1, k2) 이후에 오는 컬럼에 대해서 동등 연산이나, 범위 연산을 하게 된다
몇몇 예제를 통해 확인해보자. 이때 X 혹은 붉은 표시는 인덱스가 범위로 접근하지 못한다는 뜻이거나 해당 값이 아님을 의미한다.
<AGE, SALARY>에 관한 복합 인덱스가 있다고 가정하자.

그림을 보면 Age 이후 Salary가 정렬되어있음을 알 수 있다.
그럼으로 31을 찾고 400이 아님을 쉽게 확인 가능하다.
아래의 케이스에도 인덱스로 빠르게 조회가 가능하다.

다만, 이번 AGE > 31 & SALARY = 400의 경우는 빠르게 조회할 수 없다. 왜냐하면 AGE가 정해지지 않은 상황에서 SALARY의 정렬 상태를 보장할 수 없기 때문이다. 이럴 경우 인덱스 버뮈 연산을 하게 된다.
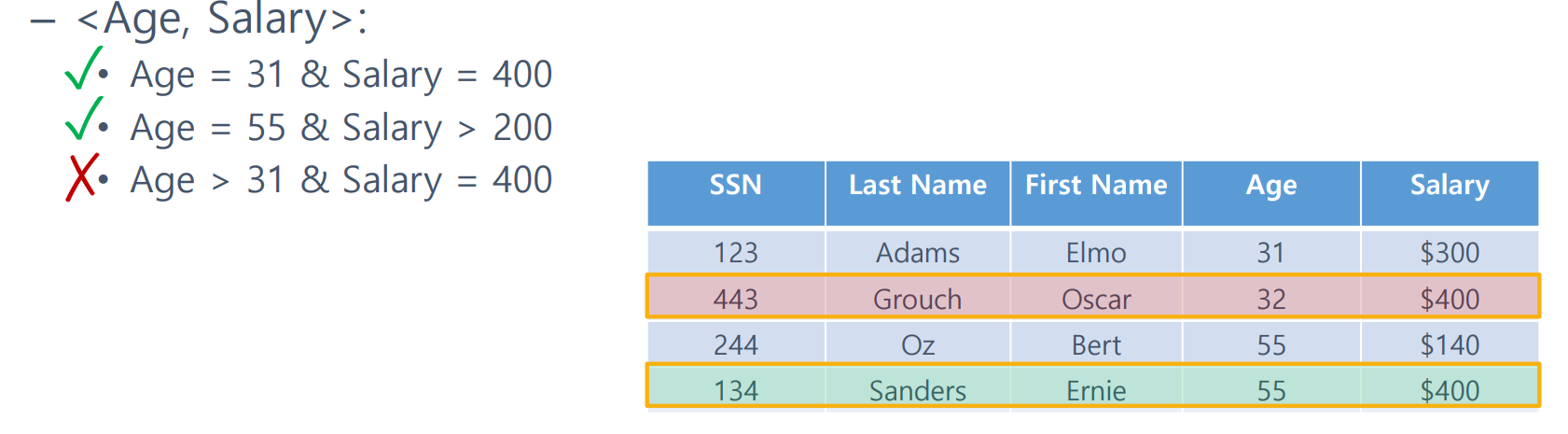
동일한 이유로 Salary만 단독 검색하는 상황에도 빠르게 index를 이용해 검색하는 것은 불가하다.

Data Entries: How are they stored?
Data entries란 index에서 값을 어떻게 저장하고 표현하는 지에 관한 내용이다. 우선 실제 값을 저장할지, 참조할지에 관하여 선택 가능하고, 두번째로는 Clustering 여부에 따라 달라진다.
Value or Pointer
Case1: By Value – Actual data record (with key value k)
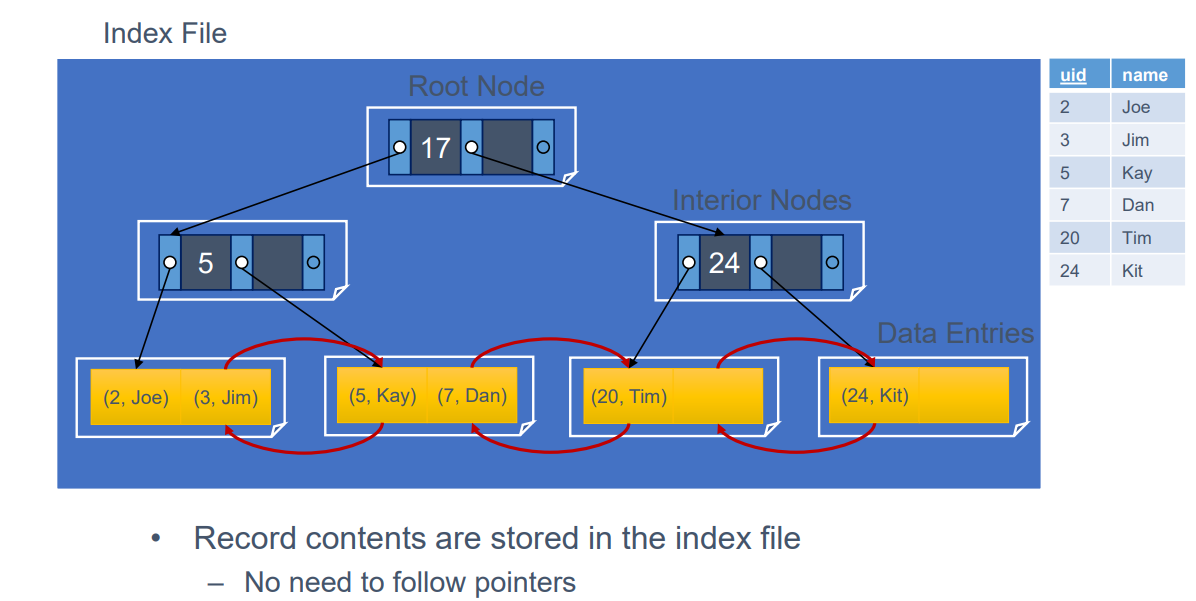
첫번째 경우는 값으로 저장하는 형태이다. 이 경우 포인터가 필요 없고, 키와 값을 분리할 필요가 없는 형태이다.
즉, 실제로 리프노드에 실제 레코드 값이 저장되어있다.
Case 2: By Reference, <k, rid of matching data record>
두번째는 값을 가리키는 참조를 생성하는 경우는 우선 키 값으로 데이터를 찾아가면 data에는 페이지 id와 슬롯 아이디가 적혀있는 형태이다. 데이터를 참조하는 것은 하나의 테이블에 여러가지 인덱스를 구현하고 또 값을 업데이트할 때 부하를 줄여주는 역할을 한다.

(2, JOE)을 찾는다면 인덱스로 키값이 2인 곳을 찾아가면 데이터에는 [1, 1]이 들어있다. 이가 뜻하는 것은 페이지 1, 슬롯 1을 찾아가라는 뜻이다. 아래 그림에 나와있듯이 해당 위치에 가면 값을 찾을 수 있다
Case 3: By List of references, <k, list of rids of matching data records>
리스트 형태로 참조하는 경우는 하나의 키가 많은 레코드를 매칭할 수 있는 구조이다. 아래의 그림을 보자.

2번째 방법과 3번째 방법의 차이는 결국 키에 따른 중복 데이터를 어떻게 처리하는가? 에 있다.
왼쪽의 경우에는 인덱스가 가리키고 있는 레코드와 일대일로 매칭이 되지만, 오른쪽의 경우에는 인덱스가 여러 개의 레코드를 가리키고 있는 형태이다.
Clustered vs. Unclustered Index

참조하는 형태의 인덱스의 경우 클러스트 되거나 클러스터링 되지 않은 형태로 만들어질 수 있다.
Clustered index를 만들기 위해서는 정렬이 필요하다. 즉, 먼저 힙파일을 우선 정렬한 후 만들어야 이후 인덱스 또한 힙파일이 정렬된, Clustered된 형태로 생성 가능할 것이다.
클러스터링 되지 않은 인덱스는 힙파일 순서가 정렬되어 있지 않기에 그림을 보면 인덱스가 데이터를 순서 없이 가리키고 있는 것을 확인 가능하다. 이런 경우 더 많은 페이지에 접근해야함으로 더 큰 I/O비용이 발생한다.
B+-TREE COSTS

Clustered Index에 삽입
- 삽입하려는 곳에 공간이 빈다면, 바로 삽입하면 되지만, 그렇지 않은 경우에는 새로운 블록을 생성하게 되고 그곳을 가리키게 된다.
- 따라서 많은 데이터가 삽입되면 힙 파일 정렬 구조는 깨지게 되며 다시 힙 파일을 정렬해줘야한다.
- 클러스터링 된 인덱스는 더 적은 I/O 를 통해서 더 빠른 조회가 가능하다. 또한 범위를 조회할 때 더 빠른 특징을 가지고 있다.
- 하지만 이를 유지하는데 많은 비용이 든다는 단점이 있다. 왜냐하면 업데이트 될 떄마다 구조가 깨지기 때문이다.
- 따라서 많은 업데이트 연산 후에 백 그라운드 연산으로, 정렬을 다시 해주거나, 힙 파일은 새롭게 더해지는 레코드를 위해서 오직 2/3 만 채우는 식으로 최적화를 한다
B+Tree Refinement: Variable-Length Keys

이전 예제들은 길이가 고정된 현태였지만, 문자열 같은 경우 가변데이터이기에 해당 케이스도 다루어보자.
PREFIX로 키 압축가변 길이 데이터를 보다 압축하여 저장하는 방법은 무엇이 있을까?
위에서의 예시처럼 변하는 부분만을 보고 Prefix를 뽑아 저장하는 방법이 있을 수 있을 것이다. 단, 이는 키에 따라서 균일하게 압출할 수는 없다.

PREFIX & SUFFIX

공통된 부분이 많기에 PREFIX를 헤더로 보내고 남은 SUFFIX만 저장하는 방식이다.
'개발 이야기 > DB(데이터베이스)' 카테고리의 다른 글
[DBMS] Hash Index (0) 2024.12.19 [DBMS] Index & B+ Tree (0) 2024.11.25 [DBMS] Heap File & Sorted File (1) 2024.11.24 [DBMS] Data Representations: Files, Pages,Records (2) 2024.11.24 [DBMS] Buffer Management (2) 2024.11.23