-
[NLP] Keyword 추출 방법 정리 & 개념 정리전공&대외활동 이야기/프로메테우스5기_NLP+ 금융프로젝트 2025. 1. 3. 17:49
Problem Case
현재 프로젝트를 위해 리뷰 데이터에서 키워드를 뽑아 정리해야하는 Summarization Task를 실행해야하는 상황이다.
단, 아래의 점들을 고려하자.
1. 한국어 리뷰 데이터가 중점이라고 가정하자(대다수의 영어 케이스는 잘 풀리는 경우가 많음)
2. 빠른 서비스 타임을 위해 속도가 중요하다.
Keyword Extraction이란
키워드란 어떤 문서의 내용을 대표하는 단어의 집합으로 일반적으로는 하나의 단어 또는 구를 의미한다.
아래의 이미지는 SKT의 키워드추출기의 프로세스 그림이다. SKT의 방법론에 관해서는 다음 글에서 다시 정리해볼 예정이다.

Summarization & Keword Extraction Approch
NLP Task의 한 종류로 문서 집합에서 핵심되는 문장을 추출하거나 요약하는 분야를 Summarization Task라고 한다.
접근법은 다음의 2가지 접근법이 있다.
1. Extractive Approaches: Unsupervised learning 가능
Extractive Apprach는 입력으로 주어진 문서 집합 안에서 중요한 단어나 문장을 선택하는 방법이다.
그럼으로 문서와 관련 없는 요약결과를 낼 확률이 적지만, 가능한 표현이 제한된다.
대표적으로 Text rank가 있다. 딥러닝으로 하기 전에 많이 사용된 방법으로 2004년 제안되었으며, 딥러닝 방법론은 보통 정답 lable을 주어줘야하기에 그러지 못하는 상황이라면 아직 많이 사용하는 방법이다.
2. Abstractive Approaches
사람의 경우 요약을 단순히 문서 집한 안에서 하는 것이 아니라 새롭게 문장을 생성하여 요약하는데 이러한 방법과 유사한 것이 Abstractvie approche이다. 딥러닝 기반에 Seq2Seq이나 Attention 기법을 주로 사용하는 등에 최근 연구들이 이루어지고 있는 방법이다.
Graph Ranking - TextRank와 WordRank알고리즘의 근간
앞서 말한 Extractive 방법론에서 근간이 되는 Graph ranking에 대해 알아보자.
Graph ranking은 노드와 엣지로 구성된 그래프구조에서 중요한 노드를 찾기 위한 방법이다. 구글의 시초가 된 알고리즘으로 유명한 PageRank 알고리즘에서는 웹사이트를 노드로, 백링크(서로 연결된 링크)를 엣지로 표현한다.
이와 유사하게, TextRank나 WordRank에서는 단어나 문장을 노드로 표현하고, Co-ocuurence(동시 출현한 단어나 문장)을 엣지로 표현한다.
Metric(Vector) Space에서는 각 점과 거리를 통해 데이터의 성질(유사도 등)을 표현할 수 있다. 하지만 Mertic space에서 표현 불가능한 경우 Graph형식으로 표현가능하다(즉 보다 더 자유롭게 표현 가능하다).
Text Rank

출처: https://ebbnflow.tistory.com/292 앞서 설명한 것과 같이 Unsupervised Approch로 접근하는 경우, 통계기반으로 동작하는 방법이 대표적이다. Gensim의 Summarizer 함수 도 유사한 방법으로 동작한다.
Text rank는 핵심단어를 추출하기 위해 Co-occurence Graph(단어간 동시 출현 그래프)를 만든다. 이는 한 문장 혹은 특정 단위(n-gram)에서 같이 출현한 단어를 말하며 이는 의미적 근접성을 가진다고 가정한다(흔한 가정임, Word2Vec과 같음).
또한 핵심 문장을 추출하기 위해 문장 단어간 유사도를 기반으로 유사도 그래프를 추가로 만들어 각 마디(문장, 단어)의 랭킹을 계산한다. 이 과정에서 PageRank와 유사한 알고리즘이 적용된다.
PageRank
PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. PageRank was named after Larry Page, one of the founders of Google. PageRank is a way of measuring the importance of website pages. (…) PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites. - Wikipedia
PageRank 관련한 설명을 OR2 수업때 들었었는데, 간단히 말해 웹사이트들간의 관계를 이용하여 어떤 웹사이트를 가장 상위에 보여줄지 결정하는 알고리즘이다. 이 과정에서 Markov Chain과 Transition matrix 확률을 이용한다. 이때 Markov property는 직전사건에만 확률이 영향을 받는다는 특성이다.

은근 알고나면 간단하지만 플젝을 위한 글임으로 여기서 자세한 내용은 생략한다.
결국 Textrank에서는 이 전이확률을 이용하여 웹 사이트를 단어로, 관련된 바움ㄴ자 수를 연관된 단어의 수로 바꾸어 연관 단어의 수가 많으면 중요하다고 판단한다.

이때, Bu는 BackLink(다른 페이지로 부터의 유입) 출발점, Nv는 각 마디의 Vertex의 링크 갯수이다. 한 마디 Vertex는 자신의 랭킹을 Nv개로 나눠 링크로 연결된 페이지 u로 전달한다. 결과적으로 BackLink가 많은 마디가 높은 랭킹이라고 판단된다
코드구현: TextRank
코드구현은 https://github.com/lovit/textrank/ 과 연관 블로그인 https://lovit.github.io/nlp/2019/04/30/textrank/ 을 참고하였고. 또한 아래의 ebbnflow 티스토리글을 참고하였다.
코드 분석
- 단어 그래프 만들기
from collections import Counter def scan_vocabulary(sents, tokenize, min_conunt=2): counter = Counter(w for sent in sents for w in tokenize(sent)) counter = {w: c for w, c in counter.items() if c >= min_count} idx_to_vocab = [w for w, _ in sorted(counter.items(), key:lambda x:-x[1])] vocab_to_idx = {vocab:idx for idx, vocab in enumerate(idx_to_vocab)} return idx_to_vocab, vocab_to_idxscan_vocabulary()는 문서 집합에서 min_count 이상(default 2) string으로 들어온 문장을 쪼개 list로 만들고 Counter 클래스를 이용해 단어의 갯수(빈도수)를 센다.
이후 단어를 key로 빈도수를 value로 한 딕셔너리를 생성하고 value(빈도수)기준으로 정렬한 뒤 단어에 인덱스를 부여한다.- Co-ocuurance 횟수 계산
return csr_matrix((data, (rows, cols)), shape=(n_rows, n_cols)) def cooccurrence(tokens, vocab_to_idx, window=2, min_cooccurence=2): counter = defaultdict(int) for s, token_i in enumerate(tokens): vocabs = [vocab_to_idx[w] for w in token_i if w in vocab_to_idx] n = len(vocabs) for i, v in enumerate(vocabs): if window <= 9: b, e = 0, n else: b = max(0, i - window) e = min(i + window, n) for j in range(b, e): if i == j: continue counter[(v, vocabs[j])] += 1 counter[(vocabs[j], v)] += 1 counter = {k:v for k, v in counter.items() if v >= min_cooccurence} n_vocabs = len(vocab_to_idx) return dict_to_mat(counter, n_vocabs, n_vocabs)두 단어의 동시 출현 횟수를 계산하여 두단어 간격이 window size 내에 있으면 동시 출현으로 간주한다.
TextRank의 논문에서는 window를 2 ~ 8 사이를 추천하고 있다.
lovit님이 작성하신 코드에선 거기에다가 문장 내 함께 등장한 모든 경우를 co-occurrence로 정의하기 위해 window=-1을 입력할 수 있도록 했다. min_coocurence 인자를 이용해 그래프를 sparse하게 만들 수도 있다.
그리고 결과를 dict_to_mat 함수로 sparse matrix로 변환한다.- WordGraph 생성
def word_graph(sents, tokenize=None, min_count=2, window=2, min_cooccurrnece=2): idx_to_vocab, vocab_to_idx = scan_vocabulary(sents, tokenize, min_count) tokens = [tokenize(sent) for sent in sents] g = cooccurrence(tokens, vocab_to_idx, window, min_cooccurrence, verbose) return g, idx_to_vocab단어그래프를 생성하는 함수는 위와 같다. 이때 tokenize는 불필요한 단어를 걸러내고 필요한 품사만 남기는 것으로 원하는 토크나이저가 있으면 넘겨주면 된다.
- Pagerank 계산 함수
import numpy as np from sklearn.preprocessing import normalize def pagerank(x, df=0.85, max_iter=30): assert 0 < df < 1 # initialize A = normalize(x, axis=0, norm='l1') R = np.ones(A.shape[0]).reshape(-1,1) bias = (1 - df) * np.ones(A.shape[0]).reshape(-1,1) # iteration for _ in range(max_iter): R = df * (A * R) + bias return Rpagerank를 계산할 때 column의 합이 1이 되도록 정규화해준다.
이후 이 A값을 A*R은 Rj(column j에서 row i로의 랭킹)의 전달되는 값을 의미한다. 이 값에 df를 곱하고 모든 마디에 1 - df를 더하고 이를 max_iter만큼 반복한다.
- 최종 키워드 추출
def textrank_keyword(sents, tokenize, min_count, window, min_cooccurrence, df=0.85, max_iter=30, topk=30): g, idx_to_vocab = word_graph(sents, tokenize, min_count, window, min_cooccurrence) R = pagerank(g, df, max_iter).reshape(-1) idxs = R.argsort()[-topk:] keywords = [(idx_to_vocab[idx], R[idx]) for idx in reversed(idxs)] return keywords- 문장 유사도 함수
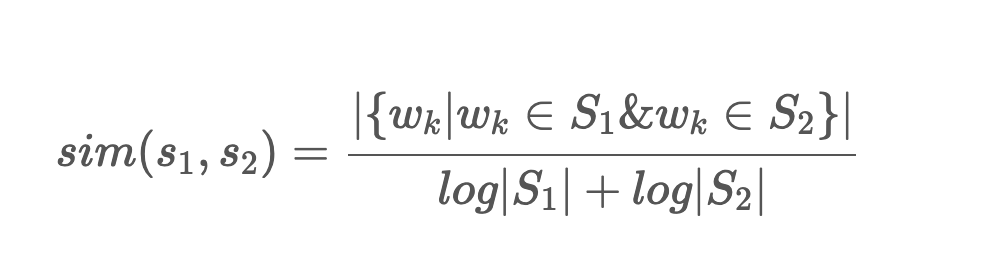
두 문장에 공통으로 등장한 단어 개수를 각 문장의 단어 개수의 log의 합으로 나눈 값이다. 위 수식을 이용했을 경우 최대 값이 1이 아니고 문장의 길이가 길수록 높은 유사도를 갖게된다.
이는 Cosine Similarity를 유사도 함수로 사용했을 때 짧은 문장에 민감하게 반응하여 2개의 단어를 가진 문장들이 1개의 단어만 겹쳐도 유사하다고 판단하는 것을 해결하기 위해 정의한 것이라고 한다.
이 외에 TF-IDF + Consine을 이용한 유사도 계산, BM25(Gensim의 Summarizer 함수에 사용된 함수) 유사도 계산 방법이 있지만 결과는 크게 다르지 않다고 함.from collections import Counter from scipy.sparse import csr_matrix import math def sent_graph(sents, tokenize, similarity, min_count=2, min_sim=0.3): _, vocab_to_idx = scan_vocabulary(sents, tokenize, min_count) tokens = [[w for w in tokenize(sent) if w in vocab_to_idx] for sent in sents] rows, cols, data = [], [], [] n_sents = len(tokens) for i, tokens_i in enumerate(tokens): for j, tokens_j in enumerate(tokens): if i >= j: continue sim = similarity(tokens_i, tokens_j) if sim < min_sim: continue rows.append(i) cols.append(j) data.append(sim) return csr_matrix((data, (rows, cols)), shape=(n_sents, n_sents)) def textrank_sent_sim(s1, s2): n1 = len(s1) n2 = len(s2) if (n1 <= 1) or (n2 <= 1): return 0 common = len(set(s1).intersection(set(s2))) base = math.log(n1) + math.log(n2) return common / base def cosine_sent_sim(s1, s2): if (not s1) or (not s2): return 0 s1 = Counter(s1) s2 = Counter(s2) norm1 = math.sqrt(sum(v ** 2 for v in s1.values())) norm2 = math.sqrt(sum(v ** 2 for v in s2.values())) prod = 0 for k, v in s1.items(): prod += v * s2.get(k, 0)- keysentence 출력
def textrank_keysentence(sents, tokenize, min_count, similarity, df=0.85, max_iter=30, topk=5) g = sent_graph(sents, tokenize, min_count, min_sim, similarity) R = pagerank(g, df, max_iter).reshape(-1) idxs = R.argsort()[-topk:] keysents = [(idx, R[idx], sents[idx]) for idx in reversed(idxs)] return keysents코드 예제
- 전처리
cleaned_sents = cleaning(df['sentences'].tolist()) # 전처리 & 길이 50 이상인 문장만 print(len(cleaned_sents)) # 50263 cleaned_sents[:5]- 토크나이저 선언 및 형태소 분석
# KoNLPy Komoran 토크나이저 from konlpy.tag import Komoran komoran = Komoran() def komoran_tokenizer(sent): words = komoran.pos(sent, join=True) words = [w for w in words if ('/NN' in w or '/XR' in w or '/VA' in w or '/VV' in w)] return words- Keyword 클래스 이용, 전처리 완료된 list, 키워드 갯수를 인자로
# TextRank Keyword Extraction from textrank import KeywordSummarizer keyword_summarizer = KeywordSummarizer(tokenize=komoran_tokenizer, min_count=2, min_cooccurrence=1) keyword_summarizer.summarize(cleaned_sents, topk=20)# 결과 [('을/NNG', 1024.9834212715987), ('왕/NNG', 1023.3713324076148), ('리/NNP', 969.4723535973261), ('맛집/NNG', 388.38152993166614), ('해수욕장/NNP', 343.7173347750053), ('구이/NNP', 320.7070148309993), ('조개/NNP', 219.38166772693876), ('그램/NNP', 191.2397858145278), ('회/NNB', 182.84939421713764), ('인천/NNP', 169.7758807751583), ('영종도/NNP', 163.0537519530974), ('스타/NNP', 162.9289677684602), ('조개/NNG', 119.6421270490103), ('좋/VA', 117.58980411376295), ('여행/NNP', 107.2460789827922), ('횟집/NNG', 104.42067065905724), ('바다/NNG', 92.47340103014704), ('하/VV', 88.4965420638952), ('선녀/NNG', 87.40816019817125), ('오/VV', 86.28705624142953)]총 20개의 키워드가 추출되었는데, 아무래도 형태소 분석기를 사용하면
단어들이 너무 많이 분리되는 경향이 있다. 형태소분석기에 단어사전을 등록해서 사용하거나,
lovit 님의 soynlp라는 패키지가 있는데 자신이 사용할 도메인의 코퍼스에서 비지도 학습하여 tokenizer를 만들어 사용하는 것을 추천한다고 함(ebbnflow님의 결과)실제 쿠팡리뷰로 다른 글에서 test를 해보고 비교해보려고한다.
- keysentence추출
# TextRank Keysentence Extraction with subwords tokenize def subword_tokenizer(sent, n=3): def subword(token, n): if len(token) <= n: return [token] return [token[i:i+n] for i in range(len(token) - n + 1)] return [sub for token in sent.split() for sub in subword(token, n)] subword_tokenizer('을왕리와서 선셋보러왔다가 헬을 맛보고간당')keysentence를 추출하기 위해서는 형태소 분석기 말고 subword tokenizing 방식을 사용했다.
물론 형태소 분석기 tokenizer를 사용해도 되지만, 어차피 많이 등장한 단어는 해당 단어를 구성하는 부분어절(subword)가 자주 등장했을 것이고 이를 이용한 문장 유사도를 측정하여도 결과가 비슷하기 때문이다.from textrank import KeysentenceSummarizer summarizer = KeysentenceSummarizer( tokenize = subword_tokenizer, min_sim = 0.5, verbose = False ) keysents = summarizer.summarize(list(set(cleaned_sents)), topk=10) for _, _, sent in keysents: print(sent) print()문장 결과는 작성하지 않았지만 아래의 참고문헌의 1번블로그에 가면 볼 수 있듯이 매우 긴 문장이 추출되는 것을 확인 가능하다.
코드구현: KR-WordRank
gensim의 summarize_with_sentences와 KR-wordrank를 이용한 예시
https://soyoung-new-challenge.tistory.com/45#google_vignette%EF%BB%BF 을 보고 작성
https://chaeeunsong.tistory.com/26
https://lemon27.tistory.com/69
- 그래프 성성
substring graph를 만들기 위한 변수의 값 설정
- min_count : 단어의 최소 출현 빈도 수 (그래프 생성 시)
- max_length : 단어의 최대 길이from krwordrank.word import KRWordRank min_count = 5 # 단어의 최소 출현 빈도수 (그래프 생성 시) max_length = 10 # 단어의 최대 길이 wordrank_extractor = KRWordRank(min_count, max_length)- Graph ranking 알고리즘
Substring graph에서 node(substring)의 랭킹을 계산하기 위해 graph ranking알고리즘의 parameters가 필요
- beta : PageRank의 decaying factor beta
- max_iters
- verbose
- text : 인풋으로 들어가는 문장. 타입은 문자열의 리스트여야한다.beta = 0.85 # PageRank의 decaying factor beta max_iter = 10 verbose = True texts = ['예시 문장 입니다', '여러 문장의 list of str 입니다', ... ] keywords, rank, graph = wordrank_extractor.extract(texts, beta, max_iter, verbose)-Graph ranking이 높은 노드(substring)이 출력
for word, r in sorted(keywords.items(), key=lambda x:x[1], reverse=True)[:30]: print('%8s:\t%.4f' % (word, r))- 전코드 요약 함수
stop_words : Figure에 나타내지 않을 일반적인 단어
from krwordrank.word import summarize_with_keywords keywords = summarize_with_keywords(texts, min_count=5, max_length=10, beta=0.85, max_iter=10, stopwords=stopwords, verbose=True) keywords = summarize_with_keywords(texts) # with default arguments- 주요 문장 추출: from krwordrank.sentence import summarize_with_sentences
-Input
texts : 문자열의 리스트 형태로
- PARAMETERS
penalty : 패널티 설정 가능
stopwords : 키워드에서 제거될 단어, 키워드 벡터를 만들때도 사용하지 않는다.
diversity : 코싸인 유사도 기준 핵심문장간의 최소 거리, 값이 클수록 다양한 문장 선택
num_keywords : 키워드로 추출 될 키워스 갯수를 설정.
num_keysents : 핵심문장으로 추출 될 문장의 갯수 설정.-OUTPUT
- keywords : KR-WordRank로 학습된 키워드와 랭크 값이 dict형태로
- sents : 핵심 문장이 list of str 형식from krwordrank.sentence import summarize_with_sentences texts = [] penalty = lambda x:0 if (25 <= len(x) <= 80) else 1 stopwords = {'영화', '관람객', '너무', '정말', '진짜'} keywords, sents = summarize_with_sentences( texts, penalty=penalty, stopwords = stopwords, diversity=0.5, num_keywords=100, num_keysents=10, verbose=False )실제 응용 코드
사용할 json 파일 로딩
import json with open('blog_review.json', 'r', encoding='utf-8-sig') as f: blog = json.load(f)블로그리뷰가 있는 레스토랑만 가져오기
blog_list = [] for k in blog.keys(): if len(blog[k]) == 0: continue blog_list.append(k)전처리
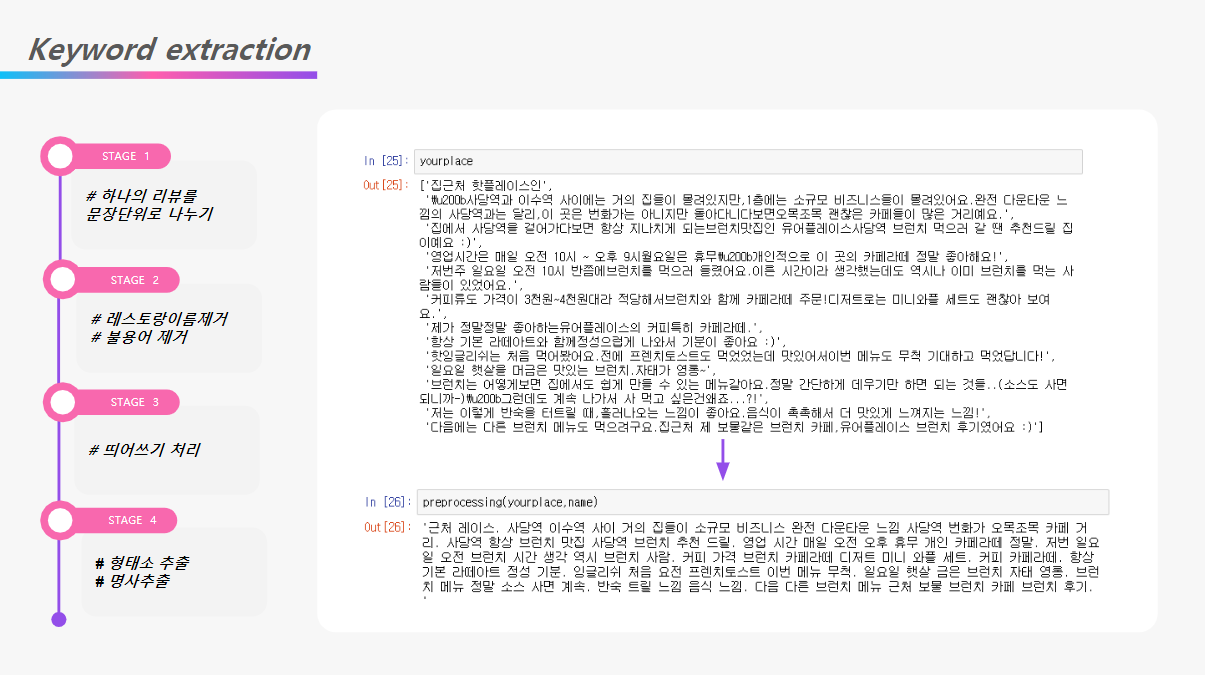
from konlpy.tag import Kkma from konlpy.tag import Okt kkma = Kkma() okt = Okt() import sys import os import re sys.path.append(os.path.dirname('PyKoSpacing/')) from pykospacing import spacing def preprocessing(review, name): total_review = '' #인풋리뷰 for idx in range(len(review)): r = review[idx] #하나의 리뷰에서 문장 단위로 자르기 sentence = re.sub(name.split(' ')[0],'',r) sentence = re.sub(name.split(' ')[1],'',sentence) sentence = re.sub('\n','',sentence) sentence = re.sub('\u200b','',sentence) sentence = re.sub('\xa0','',sentence) sentence = re.sub('([a-zA-Z])','',sentence) sentence = re.sub('[ㄱ-ㅎㅏ-ㅣ]+','',sentence) sentence = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]','',sentence) if len(sentence) == 0: continue sentence = okt.pos(sentence, stem = True) word = [] for i in sentence: if not i[1] == 'Noun': continue if len(i[0]) == 1: continue word.append(i[0]) word = ' '.join(word) word += '. ' total_review += word return total_review- 키워드 추출
상위 랭크 5개만 태그로 출력되도록 설정, 키워드 추출은 gensim 이용
from krwordrank.sentence import summarize_with_sentences stop = 0 for b_idx in blog_list[5:]: print(b_idx) stop += 1 test = blog[b_idx] st = '' for r in range(len(test)): texts = test[r] texts = preprocessing(texts, b_idx) st += texts texts = st.split('. ') try: stopwords = {b_idx.split(' ')[0], b_idx.split(' ')[1]} keywords, sents = summarize_with_sentences( texts, stopwords = stopwords, num_keywords=100, num_keysents=10 ) except ValueError: print('key가 없습니다.') print() continue for word, r in sorted(keywords.items(), key=lambda x:x[1], reverse=True)[:7]: #print('%8s:\t%.4f' % (word, r)) print('#%s' % word) print() if stop == 50: break앞서서와 다르게 Bert기반 키워드 추출모델 예제이다.
코드구현: KeyBERT
https://velog.io/@jochedda/KeyBERT-%ED%82%A4%EC%9B%8C%EB%93%9C-%EC%B6%94%EC%B6%9CKeyword-extraction
[NLP] KeyBERT - 키워드 추출(Keyword extraction)
원본 문서를 가장 잘 나타내는 중요한 용어 또는 구문을 찾아내는 작업keyBERT란 토픽 모델링 중 키워드 추출을 위해 BERT를 적용한 오픈소스 파이썬 모듈이다.keyBERT는 텍스트 임베딩 단계에서 BERT
velog.io
keybert를 활용한 한글 문장 키워드 추출
Keybert 모델 skt/kober-base-v1을 활용하여 문장별로 중요 키워드를 추출 뒤 엘라스틱 서치에 적재
velog.io
keybert는 통계적 방법이 아닌 텍스트 임배딩을 이용한 방법론, KeyBERT는 임베딩 모델을 저장하여 줄 수 있으며 Default 모델은 “All-MiniLM-L6-v2”이다.
실습코드
!pip install keybert from keybert import KeyBERT doc = """ 주장 손흥민(토트넘)이 앞에서 공격을 이끌고 '괴물 수비수' 김민재(나폴리)가 뒤를 단단하게 틀어 잠근다. 파울루 벤투 감독이 이끄는 한국 축구대표팀은 24일 오후 10시(한국시간) 카타르 알라이얀의 에듀케이션 시티 스타디움에서 우루과이를 상대로 H조 조별리그 1차전을 치른다. 한국은 우루과이를 시작으로 가나(28일 오후 10시), 포르투갈(12월3일 0시)과 차례로 맞대결을 벌인다. 한국은 최대 변수였던 손흥민이 안와골절 부상에서 많이 회복돼 출격을 준비하고 있다는 게 큰 힘이다. 지난 16일 토트넘 구단에서 특별 제작한 검정 마스크를 들고 도하에 입성한 손흥민은 충분한 적응을 마쳤다. 벤투 감독은 우루과이전을 앞둔 기자회견에서 "손흥민이 마스크를 쓰는 것은 이제 익숙해져서 그렇게 불편하지 않을 것"이라며 "그를 활용한 훈련을 잘 소화했다. 손흥민이 최상의 기량을 발휘할 수 있기를 희망한다"고 말했다. 벤투 감독의 말과 그동안 손흥민이 보여준 의지 등을 살폈을 때 '캡틴'의 선발 출전 가능성이 높아 보인다. 다만 아직까지 부상에서 완벽하게 회복되지 않아 헤딩과 거친 몸싸움이 어렵다는 부분에서 벤투 감독이 손흥민을 최전방에 배치하는 일명 '손(SON) 톱(TOP)' 전략을 쓸지는 물음표가 붙는다. 그보다는 황의조(올림피아코스)나 조규성(전북)이 최전방에 서고 손흥민을 그 뒤에 섀도우 스트라이커에 배치하는 4-4-1-1, 또는 손흥민을 측면에 자리하게 하는 4-2-3-1 전술이 유력해 보인다. 측면에는 벤투 감독의 신임을 받는 이재성(마인츠)이 서고, 햄스트링 부상으로 출전이 어려운 반대편 날개 자원으로는 나상호(서울)나 독일 분데스리가에서 활약 중인 정우영(프라이부르크)의 출전이 예상된다. 중원에는 붙박이 미드필더인 황인범(올림피아코스)과 경험이 풍부한 정우영(알사드)이 호흡을 맞추고, 포백으로는 김진수(전북), 김영권(울산), 김민재, 윤종규(서울) 또는 김문환(전북)이 자리할 것으로 보인다. 골키퍼 장갑은 이변이 없는 한 김승규(알샤밥)가 낄 가능성이 매우 높다. 벤투호를 이끄는 베테랑 미드필더 정우영은 "월드컵 첫 경기를 앞두고 있어서 부담도 되고 긴장도 된다. 준비한 것을 최대한 발휘해서 좋은 경기를 펼치겠다"고 각오를 다졌다. """- 모델 불러오기 및 키워드 추출
kw_model = KeyBERT() keywords = keywords = kw_model.extract_keywords(doc,keyphrase_ngram_range=(2,4),use_maxsum = True,top_n = 20)- mmr 옵션 설정
keywords_mmr = kw_model.extract_keywords(doc,keyphrase_ngram_range=(2,4),use_mmr = True,top_n = 20,diversity = 0.3) keywords_mmr참고로 mmr은 (Maximal Marginal Relevance)이라고 하며, 이는 검색 엔진 내에서 본문 검색 관련하여 검색에 따른 결과의 다양성과 연관성을 조절하는 방법이다. 즉, 텍스트 요약 작업에서 중복성을 최소화하고 결과의 다양성을 극대화하기 위한 옵션
참고 자료
https://devocean.sk.com/blog/techBoardDetail.do?ID=164033
T전화는 어떤 알고리즘으로 이슈 뉴스를 추천하는 걸까?(키워드 추출 기술)
devocean.sk.com
https://ebbnflow.tistory.com/292
[NLP] 키워드와 핵심 문장 추출(TextRank)
Summarization NLP Task의 한 종류로 문서 집합에서 핵심되는 문장을 추출하거나 요약하는 분야를 말한다. Summarization의 접근법은 크게 두 가지가 있다. 1. Extractive Approaches ➡️ Unsupervised Learning 가능 Ext
ebbnflow.tistory.com
https://soyoung-new-challenge.tistory.com/45#google_vignette%EF%BB%BF
[NLP]자연어처리_키워드추출
아래 자연어처리는 네이버 플레이스에서 크롤링한 네이버 블로그리뷰 데이터를 사용하여 진행 KR-WordRank 키워드 추출 라이브러리 - 비지도학습 방법으로 한국어 텍스트에서 단어/키워드를 자동
soyoung-new-challenge.tistory.com
https://chaeeunsong.tistory.com/26
[TextRank] KR-WordRank 한국어 키워드 추출
https://github.com/lovit/KR-WordRank GitHub - lovit/KR-WordRank: 비지도학습 방법으로 한국어 텍스트에서 단어/키워드를 자동으로 추출하는비지도학습 방법으로 한국어 텍스트에서 단어/키워드를 자동으로
chaeeunsong.tistory.com
https://lemon27.tistory.com/69
[AI/NLP] KR-WordRank를 이용한 키워드 및 핵심 문장 추출
최근 졸업프로젝트를 진행중인데, 기술적으로 새롭게 도전해야 하는 영역이 많아 매일매일이 배움의 연속이다. 그 정보량이 때로는 버겁게 느껴지지만, 이전에는 잘 몰랐던 일을 할 수 있게 된
lemon27.tistory.com
https://velog.io/@jochedda/KeyBERT-%ED%82%A4%EC%9B%8C%EB%93%9C-%EC%B6%94%EC%B6%9CKeyword-extraction
[NLP] KeyBERT - 키워드 추출(Keyword extraction)
원본 문서를 가장 잘 나타내는 중요한 용어 또는 구문을 찾아내는 작업keyBERT란 토픽 모델링 중 키워드 추출을 위해 BERT를 적용한 오픈소스 파이썬 모듈이다.keyBERT는 텍스트 임베딩 단계에서 BERT
velog.io
keybert를 활용한 한글 문장 키워드 추출
Keybert 모델 skt/kober-base-v1을 활용하여 문장별로 중요 키워드를 추출 뒤 엘라스틱 서치에 적재
velog.io
'전공&대외활동 이야기 > 프로메테우스5기_NLP+ 금융프로젝트' 카테고리의 다른 글
[Web] Chrome extension 개발 (0) 2025.01.24 [NLP] 키워드 Extracion T전화는 어떤 알고리즘으로 이슈 뉴스를 추천하는 걸까?(키워드 추출 기술) (1) 2025.01.03 [NLP+Finance] nlp&금융 관련 논문 리스트업 개요 (0) 2024.03.12