-
[Martrix Factorization: Netfilx] 리뷰(IEEE 2009)Paper Review(논문이야기) 2023. 7. 24. 21:46
Introduction
Modern Consumer are inudated with Choices(현대 소비자들은 선택에 매몰되어있다)
Matching consumers with the most appropriate products is key to enhancing user satisfaction and loyality.
(소비자를 매칭하는 문제는 소비자 만족과 충성도에 매우 주요한 구성요소 중 하나이다)
Customers have proven willing to indicate their level of satisfaction with particular movies, so a huge volume of data is available about which movies appeal to which customers. Companies can analyze this data to recommend movies to
particular customers.(소비자들은 특정 영화에 관해(제품) 만족도를 나타낼 수 있다는 것이 증명되었기에 어떤 영화가 어떤 소비자에게 어필될 수 있는지에 대해 대량의 데이터를 사용가능하고 이는 추천에 이용 될 수 있다)
BackGround
Recoomender System(추천 시스템)
추천 시스템은 크게 두 전략 중 하나를 사용한다.
1. Content based Filtering(콘텐츠의 정보를 기반으로 추천)
아이템과 유저 자체의 정보를(장르, 배우, 박스 오피스 점수 / 유저의 취향, 나이, 성별(demograpthic information) 등) 이용해 매칭하는 것
문제는 not be availiable or easy to collect(정보를 모으기가 어렵다)
2. Collaborative Foiltering(협업 필터링)
Domain Free라는 장점을 지니는 방식으로 사용자와 아이템 간의 상호 상관 관계를 분석하여 새로운 사용자-아이템 관계를 찾아줌(사용자의 과거 경험과 행동방식에 의존한다)
문제로는 Cold Start 문제가 있음
Cold Start Problem: 새로운 사용자나 새로운 아이템의 경우 기존의 경험, 혹은 데이터가 없기에 추천을 하기 어려운 문제를 말함
협업 필터링은 다시 Neighborhood Methods와 Lantent Factor Model로 크게 구분된다.
Matrix Factorization은 Latent Factor Model에 해당하는 방법이다.
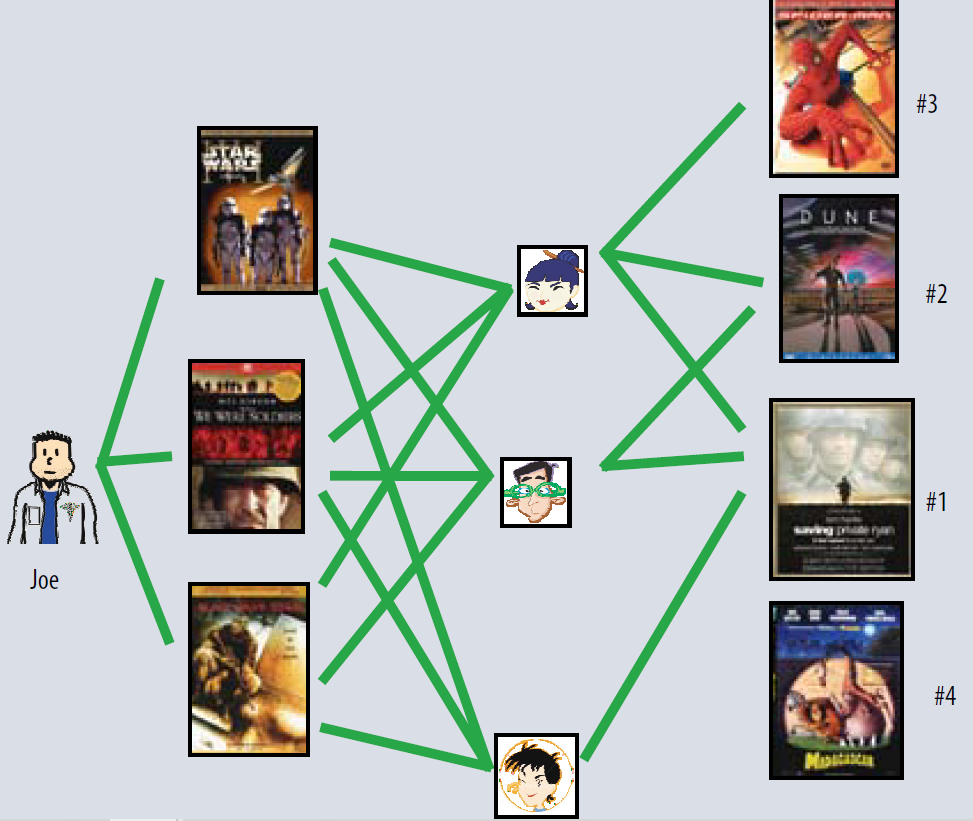
The user-oriented neighborhood method. Joe likes the three movies on the left. To make a prediction for him, the system finds similar users who also liked those movies, and then determines which other movies they liked. In this case, all three liked Saving Private Ryan, so that is the first recommendation. Two of them liked Dune, so that is next, and so on. Neighborhood mehtods는 아이템과 유저 관계를 계산하는 것이 목적이다.
위 그림을 보면 Joe가 특정 영화들을 좋아하는 특성이 있다면, 이와 비슷한 특성을 지닌 유저들이 좋아한 다른 영화를 추천해주는 모습을 볼 수 있다.

A simplified illustration of the latent factor approach, which characterizes both users and movies using two axes—male versus female and serious versus escapist. Latent Factor Model은 유저와 아이템을 잠재 벡터(Latent vector)로 매핑하여 선호도를 측정하는 것이다.
Rating data에서 추촌된 20~n개의 요소들에게 대해, 아이템과 사용자들을 모두 맵핑하여 점수를 설명하는 방식이다. 주어진 데이터로는 알 수 없는 사용자와 아이템의 숨겨진 특징을 Latent vector로 표현하고자 한다.
이 때 user i의 item j에 대해 예측되는 rating은 유저와 아이템 벡터의 내적값과 동일하다.
Martix Facotirzation model
Matrix fatorcization은 아이템-점수 패턴으로 부터 추론된 vector로 user와 item을 모두 표현하여 학습시키는 기법을 의미한다.
아이템과 사용자 간의 높은 상관관계를 지닐 경우 아이템을 유저에게 추천한다.
Data for recommendation
추천 시스템의 경우 다양한 data를 사용할 수 있다.
Data는 크게 Explicit data, Implicit data 2 종류가 있다.
Explicit Data(직접 + 데이터): 평점 기록처럼 유저가 자신의 선호도를 직접(Explicit) 표현한 Data를 Explicit Data
라고 한다. 즉 유저의 preference가 직접 표현된 데이터이다. 매우 유용하지만 얻기가 쉽지 않다Implicit Data(간접 + 데이터):
간접적으로 선호를 나타내는 데이터로, 예시로 검색 기록, 시청시간, 방문 페이지, 구매 내역 등 다양한 데이터를 의미한다. 수집의 난이도가 상대적으로 낮고 데이터 양이 많다.
크게 4가지 특징이 있다.
1. 부정적인 피드백이 없다(No Negative Feedback):
유저가 어떤 영화를 본 기록이 없을 때 유저가 그 영화를 싫어해서 보지 않았는지 혹은 그저 알지 못해서, 검색하지 못해서 보지 않았는지 알 수 없습니다. 즉, 불호 정보가 포함되어 있지 않다.
2. 잡음이 많다(Inherently Noisy) :
어떤 영화를 봤다고 해서 유저가 그 영화를 좋아한다고 말하기 힘듭니다. TV 프로그램의 경우 그냥 틀어놓고 다른 일을 했을 수도 있다.
3. 신뢰도를 의미한다.(The numerical value of implicit feedback indicates confidence) :
높은 값은 높은 선호도를 의미하는 것이 해당 데이터가 신뢰할만한 데이터임을 의미한다고 해석합니다. 한 번 보고만 영상보다는 자주, 오래 본 영상이 유저의 선호도, 의견을 표현했을 확률이 높기 때문입니다.
4. 적절한 평가지표가 필요하다(Implicit-feedback Recommender System need appropriate measurement):
Explicit data와 다르게 새로운, 혹은 적합한 평가지표가 필요하다.Matrix Factorization의 장법 중 하나가 추가적인 데이터를 사용할 수 있다는 점이다. Explicit data가 충분치 않거나 사용 불가능 할때, implicit feedback을 사용 가능하다.
Basic Matrix-Factorization Model
Matrix Factorization은 사용자와 아이템을 차원(f)의 공동 latent factor space에 매핑한다.
이 안에서 user-item interaction은 백테의 내적으로 표현된다.

r_ui: rating of user u on item i q_i: item i의 벡터, p_uuser u의 vector q는 아이템 i가 해당 요소를 가지고 있는지 양수 혹은 음수의 값으로 표현
p는 유저 u가 해당 아이템에 관한 각 factor에 긍정적인지 부정적인지 표현하는 값
여기서 핵심적인 challenge는 factor vector에 대한 각 아이템과 사용자의 매핑을 계산하는 것이다.
기존에 가장 잘 알려진 방법 중 하나인 Singular value decomposition(SVD)와 이는 매우 유사하지만, 사용자-아이템 행렬의결측치가 많기 때문에(수천개의 아이템 중 우리가 별점을 매긴 것은 적다) 이를 적용하는 것은 문제가 될 수 있다. 또한 missing value을 임의로 지정하는 경우 overfitting 문제가 발생 할 수 있다.
다라서 관측된 항만을 학습에 사용하고 정규화 term을 이용해 overfitting을 보완하는 식을 이용한다.

r: 주어진 rating 값(실제 평점)
K: 실제 interaction 된 user item 쌍
lamda: overfitting 조절하는 hyperparameter
Learning Algorithms
1. Stochastic gradient descent (SGD)

SGD는 각각의 training set에 관해 에러를 계산하고 learning rate만큼 경사하강법을 적용하는 방식
2. Alternation Least Squares(ALS)
SGD에서 p와 q는 알려져있지 않기에 convex하다고 할 수 없는 식의 term이다.
그러나 둘 중 하나의 값을 고정한다면 식이 quadratic form으로 바뀌기 때문에 convex문제로 바뀌게 된다.
따라서 q를 고정하고 p를 최적화, 이후 p를 고정하고 q를 최적화하는 방식으로 두번 계산하게 된다.
따라서 일반적으로 SGD가 ALS보다 빠르고 쉽지만 ALS는
1. 시스템이 병렬화를 지원하는 경우
2. 시스템이 implicit한 data에 중점을 두는 경우
더 유리하다.
Adding term to basic model
Add Biases
Matrix factorization의 장점은 다양한 데이터를 추가하고 다야아한 요구사항을 처리할 수 있는 유연성이다.
Bias를 추가하는 이유는 사용자나 아이템 자체의 특성에서 오는 영향이 있기 때문이다. 이를 Biases 혹은 Intercepts라고 한다.
Bias 식은 다음과 같다.

해당 식의 각 요소는 다음과 같다.
u: 전체 rating의 평균
b_i: 특정 item에 관한 bias(예를 들어 특정 영화가 전체 평점에 비해 0.2가 좋은 경우)
b_u: 특정 유저에 관한 bias(특정 유저 a가 비평가라 전체적으로 평점을 적게 주는 경우)
이를 반영하면 rating의 예측은 아래와 같고

그럼 이를 반영한 최종 minmization 식은 아래와 같다.

Add Addtional input
앞서 언급된 cold start Problem 해결을 위해 추가적인 input data가 들어가는 경우가 있을 수 있다.
1. user u의 item i에 관한 implicit feedback을 적용하는 경우
N(u): set of item that user u expressed implicit preference

해당 x 벡터를(잠재벡터) 정규화하는 것이 유용하기에 위와 같이 표현 가능하다.
2. user에 관한 demographics 정보를 추가하는 경우
A(u): user의 demographic attribute, y는 잠재벡터에 해당
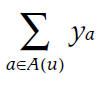
이 둘을 Matirx factorization model에 적용하면 아래와 같은 식이 나온다.

Add Temporal effect
지금까지 모델은 시간에 따른 영향을 고려하지 않았지만, 실제로는 선호는 시간에 따라 변한다.
총 3가지 effect를 반영하는데 이는
b_i(t): item bias(아이템 인기는 시간이 지남에 따라 변할 수 있다)
b_u(t): user bias(사용자 성향은 시간이 지남에 따라 변할 수 있다)
p_u(t): user preference (아이템에 대한 사용자 선호도 역시 시간이 지남에 따라 변할 수 있다)
이다.
논문에서는 예시로 영화의 주인공이 인기가 많아지는 경우, 후하게 점수를 매기던 사람이 비평가가 되는 경우, 영화의 취향이 바뀌는 경우를 예시로 든다.
이를 고려한 식은 다음과 같이 변한다.
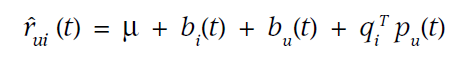
Add Confidence level
모든 데이터가 동일한 신뢰도를 가지지 않는다. 어떤 사용자의 경우 아무 생각없이 모두 5점을 줄 수도 있고, 또한 implicit feedback을 중심으로 구축된 시스템은 사용자의 정확한 선호도를 정량화 하기 어렵다.
이를 반영하기 위해 신뢰도지표를 추가하는 것이 중요하다. 신뢰도는 행동 빈도에 따른 값으로 표현가능하기도 한다.
특정 show를 얼마나 자주 보았는지, 길게 보았는지 등으로 정의 가능하다.
c_ui라는 신뢰도를 반영한 최종식은 다음과 같다.

Netflix Prize Competition
- 2006년 Netflix의 SOTA Recsys model 개발 대회
- 100 million rating
- 500,000 customer
- 17,000 movie
- Explicit 1-5 rating
- RMSE
- 48,000 team from 182 countries
이라는 조건으로 진행된 대회에서 논문 저자는 논문에 적힌 MF 모델을 기반으로 기존 알고리즘 대비 9.46%의 성능을 향상 시킴

factor 2개를 기반으로 영화를 분류한 예시 첫번째 요소 벡터는 남성, 청소년 관객 위주의 코미디 영화와 공포영화이면 양수, 반대로는 진지한 분위기와 여성주연의 드라마나 코미디이면 음수의 값을 주었고, 두번째 요소는 상단일 수록 비평가들이 좋아하는 영화, 하단일수록 주요 영화들이 위치해있다. 영화가 장르에 맞게 잘 분리되어있음을 확인 가능하다.또한 결과적으로 아래와 같은 모델의 성능향상을 그래프로 제시하고 있다(rmse 지표 이용)
Model Implementation
차후 github 링크 추가 예정
'Paper Review(논문이야기)' 카테고리의 다른 글