-
[PyTorchZerotoAll 내용정리] 10: Convolution Neural Network(CNN)ML&DL 이야기/Pytroch 2023. 10. 9. 10:55
Pytorch Zero To All 강의를 Base로 삼아서 내용을 작성 및 정리하였습니다
24.1.28: LGAimers강의 중 주재걸 교수님의 CNN 강의의 일부내용을 포함하였습니다Basic Idea of CNN

CNN 기존의 이미지 기반 모델들의 경우, 여러 상이한 이미지 모델들에 관해서 잘 구분하거나, 파악하지 못하는 문제들이 있었다. 사람의 경우 이미지를 판단할 때 일부 특정패턴을 보고 그 중 전부가 아닌 일부가 이미지에 있다면 이를 보고 그 이미지를 판단한다. CNN의 경우에도 수많은 이미지 중 특정 패턴을 학습하여 이를 이용해 이미지를 확인하겠다는 것이 main Idea이다.


즉, 위의 이미지처럼, 여러 학습 데이터에서 특정한 패턴이 반복된다면, 이미지에서 해당 패턴이 존재하는 것을 학습한다.
이렇게 구해낸 패턴이 있는 필터를 convolution filter라고 한다.그러면 이후 학습한 패턴과, 주어진 다른 이미지의 부분과의 유사도를 각 pixel 값들과의 곱셈의 합으로 구할 수 있다. 이를 통해 얻어내는 매칭의 정도를 나타내는 결과이미지를 activation map이라고 한다.
추가적으로 한번의 학습에 하나의 이미지가 아닌 여러 이미지의 결합으로 데이터가 들어온다면(ex:RGB 데이터) 이를 channel(혹은 depth)이라고 한다.
이런 기본 아이디어를 가지고 아래의 내용을 보자.
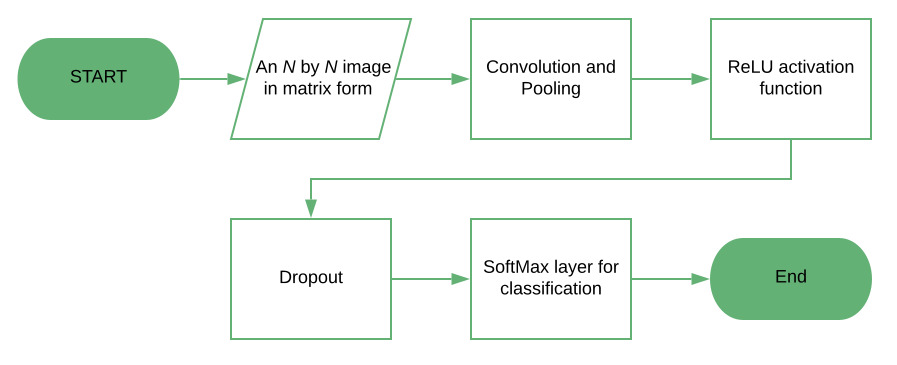
Convolution Neural Network 구조

CNN 구조 이미지 CNN의 구조는 다음과 같다.
특징 추출 단계(Feature Extraction, Conv Layer)
Convolution과 Pooling을 반복하면서 이미지의 feature를 추출
- Input : 이미지
- Convolution Layer : 필터를 통해 이미지의 특징을 추출
- Activation Layer: ReLU를 이용한다 Pooling 전에 수행하기도 이후에 수행하기도 한다
- (Batch Norm): Batch normalization 수행(2015년 발표 이후 ResNet 적용, 이후부터 활발히 사용)
- Pooling Layer : 특징을 강화시키고 이미지의 크기를 줄임 ( sub-smapling ), 일부 conv layer에서는 생략가능(con-relu, con-relu- pooling의 순서로도 사용가능)
이미지 분류 단계(Classification, FC Layer)
- Flatten Layer : 데이터 타입을 1차원 형태로 변경. 입력 데이터의 shape 변경만 수행(FC layer에 넣기 위한 input변형)
- Dropout Layer: 드롭아웃 수행, generalzation 강화
- Softmax Layer : Classification수행
- output : 인식 결과
위의 그림에서 확인하라 수 있는 또 한가지 특징은 뒤로 갈수록 filter의 수가 많아진다는 것인데, 그 이유는 두가지 측면에서 해석 가능하다.
첫 번째는 연산량이다. 처음에는 이미지가 크기 때문에 적은 양의 conv filter로만 계산을 해도 굉장히 많은 연산이 요구되지만, 하지만 마지막 layer까지 가다보면 이미지의 크기(or feature map)가 매우 작아지게 되는데(conv layer의 효과 + pooling에 따라) 이때는 많은 conv filter로 convolutoin 연산을 적용해도 그 계산량이 크게 차이가 나지 않을 것이기에 가능하다.
두 번째는 추출한 feature의 특징이다. 저층 layer에서 뽑아낼 edge 정보는 굉장히 단순한 구조로, 직관적인 형태이다. 그렇기 때문에 많은 형태를 추출할 필요가 없다. 하지만 모양이 점점 추상적으로 바뀌어 갈수록 점점 형태가 복잡진다. 예를 들어, 강아지의 윤곽선을 만들기 위해서 쓰이는 edge가 직선, 대각선, 곡선 3가지라고 한다면 강아지의 귀를 만들기 위해서는 세모, 네모, 동그라미, 다각형, 구부러진 귀 모양 등등 더 다양하고 추상적인 형태가 필요하기에 깊은 영역으로 갈수록 보통 필터의 갯수를 늘린다.
각 구조의 파트에 해당하는 내용은 아래에서 하나씩 확인해보자.
Why CNN?

DNN의 문제점과 CNN의 필요성을 보여주는 slide, 가중치의 수의 차이를 보자 일반적으로 DNN의 경우 우리는 지금까지 1차원 data만을 이용해 왔다.
따라서 이미지의 경우 2차원, 3차원의 data이기 때문에 이를 flatten시켜서 1차원 data로 변경시켜야한다.
이 과정에서 이미지의 Spatial/topological Information이 손실되게 된다(동시에 회전, 이동 등의 단순 이미지 변형도 다른 data로 인식한다)
또한 막대한 양의 model parameter가 필요하다는 문제도 있다.
그림과 같이 1000*1000 pixel의 이미지를 다룬다고 가정하면 우리는 파라미터로 $10^{3*2} x 3$이라는 굉장히 많은 양의 뉴런이 필요할 것이다.
이를 해결하기 위해 CNN이 탄생하였다.
CNN의 가장 핵심적인 아이디어는 이미지의 특정 부분(patch)만을 보아, 그 부분의 정보와 주변의 정보간의 연관성을 잘 모은다, 이후 해당 patch에서 특정 feature 값을 뽑아내려고 하는 것이다.
CNN에서는 모델이 update하는 것은 filter의 가중치이다.
Convolution이란(합성곱)
CNN에서 Convloution의 수학적인 정의를 확인할 필요는 없지만(간단히 필터와 input을 결합하는 수식이라고만 봐도 무관하지만), 그래도 하다보면 궁금해지기에 간단히 정의해보았다.
Convolution은 선형성(Addivitiy, Homogeneity)을 가지고, 시간에 따라 변화하지 않음(Time-invarient)의 특징을 가지는 시스템이다. 추가로 수학적인 내용 및 연산을 더 빠르게 하기위한 고속푸리에 변환에 관한 내용은 아래의 링크를 확인하자.
https://secundo.tistory.com/71
[ML] Convolution 합성곱의 정의와 FFT 고속푸리에 변환에 관하여
아래의 자료들을 모두 참고하여 작성하였다 https://m.blog.naver.com/ycpiglet/222556985523 [신호및시스템] 컨볼루션(Convolution)이란? - 시스템을 몰라도 입력과 임펄스 응답을 통해 출력(결 신호 및 시스템(Si
secundo.tistory.com
Convolution은 연속 시스템에서 아래와 같이 정의되며, 이산시스템에서는 적분을 시그마로만 바꾸어주면 된다.

convolution, x는 원형 데이터, h는 필터함수이다 합성곱 식을 살펴보면 두 함수 $f$, $g$가 있는데(f = x, g = h)
일반적으로 사용될때 함수 $f$는 우리가 가지고 있는 본래의 신호, 행렬, 이미지 등이 원본 데이터이고,
이때 함수 $g$는 필터, 가중치 같은걸로 표현된다.
이 두 함수를 합성곱 하면? 주어진 신호, 행렬, 이미지를 우리가 원하는 함수로 변형시킬 수 있다.
즉 간단히 이야기하면, 함수 $f$ 주어졌을때 우리가 원하는 목적에 따라 함수 $g$를 선정하여 분해, 변환, 필터링 할 수 있는 것이 Convolution인 것이다.

convolution의 예시 이제 CNN에 사용되는 용어들을 확인해보자.
Kernel(Filter) & Stride
위에서 말햇듯이 Convolution에 h에 해당하는 함수부분은 필터가 들어가는 부분이다.
Filter 혹은 Kernel이라고 불리는 것은 일정공간으로 이동(Stride)해가며 입력데이터 적용된다.
이를 통해 우리는 목적이었던, 이미지 데이터의 압축에 성공하였다.

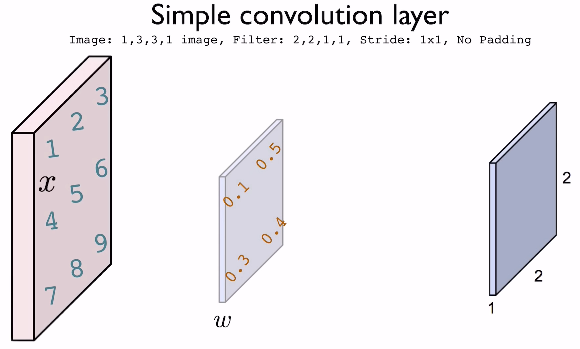
합성곱 연산에 관한 이해를 돕기위한 그림 즉, 용어를 정리하면, 이미지의 특징을 찾아내기 위한 필터부분을 Filter 혹은 Kernel이라고 한다.
또한 커널은 입력 데이터를 지정된 간격으로 순회하면서 합성곱 계산을 하는데, 이때 이동하는 간격이 바로 Stride이다.
Stide가 클 수록 계산 복잡성은 줄어들지만(데이터의 차원이 작아짐) 동시에 중요한 특성을 놓칠 수도 있다.
또한 이 Kernel의 크기(size)는 (1,1), (3,3) 등 작은 커널의 크기는 이미지의 세부사항을 캡쳐하지만, (5,5) 등의 큰 크기는 더 추상적인 부분을 캡쳐할 것이다. 이 크기를 선택하는 것은 실험적인 부분임으로 더 작은 커널의 크기로 필요한 경우 늘리는 것이 좋다. 커널의 크기가 클 수록 계산 복잡성은 늘것이다.
Depth( # of Channel)
Depth 혹은 channel은 사용된 필터의 개수와 같다.
일반적으로 이 depth는 우리가 추출하고자 하는 Feature의 수와 동일하다( 채널은 서로 다른 관점에서 본 동일한 정보라고 볼 수 있으며, 즉, 우리가 몇개의 관점에서 볼 것인지에 따라 채널의 수가 정해진다)
아래 링크의 내용에 따라 조금 더 글을 추가하면 아래와 같다.
https://stackoverflow.com/questions/32294261/what-is-depth-of-a-convolutional-neural-network
What is Depth of a convolutional neural network?
I was taking a look at Convolutional Neural Network from CS231n Convolutional Neural Networks for Visual Recognition. In Convolutional Neural Network, the neurons are arranged in 3 dimensions(height,
stackoverflow.com
UPDATE:
CNN의 각 layer에서는 이미지에 관한 규칙(regularities)을 학습한다. 첫번째 layer에서는 곡선과 모서리이며, 레이어에 따라 더 깊이 들어가면 색깔, 모양, 객체 등 더 추상화된 규칙성을 뽑아낼 것이다.
http://www.datarobot.com/blog/a-primer-on-deep-learning/
UPDATE 2:
위의 링크의 첫번째 그림을 보면, Red input layer는 이미지를 포함하고 있기에, width랑 height는이미지의 차원의 크기(pixel의 크기)가 될 것이고 depth는 3이 될것이다(Red, Green, Blue). 즉, CNN에서 기본적으로 depths는 RGB로 대표되는 색상의 수와 같다. 더하여 Eve
UPDATE 3:
The first convolutional layer filters the 224×224×3 input image with 96 kernels of size 11×11×3 with a stride of 4 pixels. 이라는 글의 내용처럼 depth는 우리가 디자인하는 필터의 수와 같다. 그럼으로 3개로 한정지을 필요는 없다.Padding
필터를 적용하게 되면 밑의 이미지처럼 결과값의 크기가 작아지는 것을 확인 가능하다.

ConvNet은 하나의 필터를 한 번 적용하는 것이 아니라 여러 단계에 걸쳐 필터를 연속적으로 적용하여 특징을 추출하게 되는데 처음에 비해 특징이 소실 될 수 있다.
따라서 원래의 이미지 크기만큼 값을 유지하기 위해, 입력 이미지 행렬의 가장자라이 0값을 추가적으로 넣어 키운 다음 필터를 적용한다. 이것이 Padding(0-padding)이다.
Activation Function(ReLU)
이후 추출된 특징에 활성화 함수를 적용한다.
특징의 값은 정량적인 숫자로 나오기에 해당 특징을 가지고 있다와 없다로 바꾸어주는 과정이 필요한데, 이것을 활성화 함수를 통해 변경한다.
대표적인 활성화 함수로는 시그모이드(Sigmoid) 함수와 ReLU 함수가 있지만, 보통 ReLU을 이용한다.

그 이유는 예전 CNN의 가장 큰 문제 중 하나가 Gradient Vanishing 문제였다.
신경망이 깊어질 수록 그 문제가 커지는데, 기본적으로 CNN의 경우 신경망의 깊이가 깊은 편이기에 해당문제가 더 자주 발생하였다. 따라서 이를 방지하기 위한 ReLU를 이용한다.
Pooling

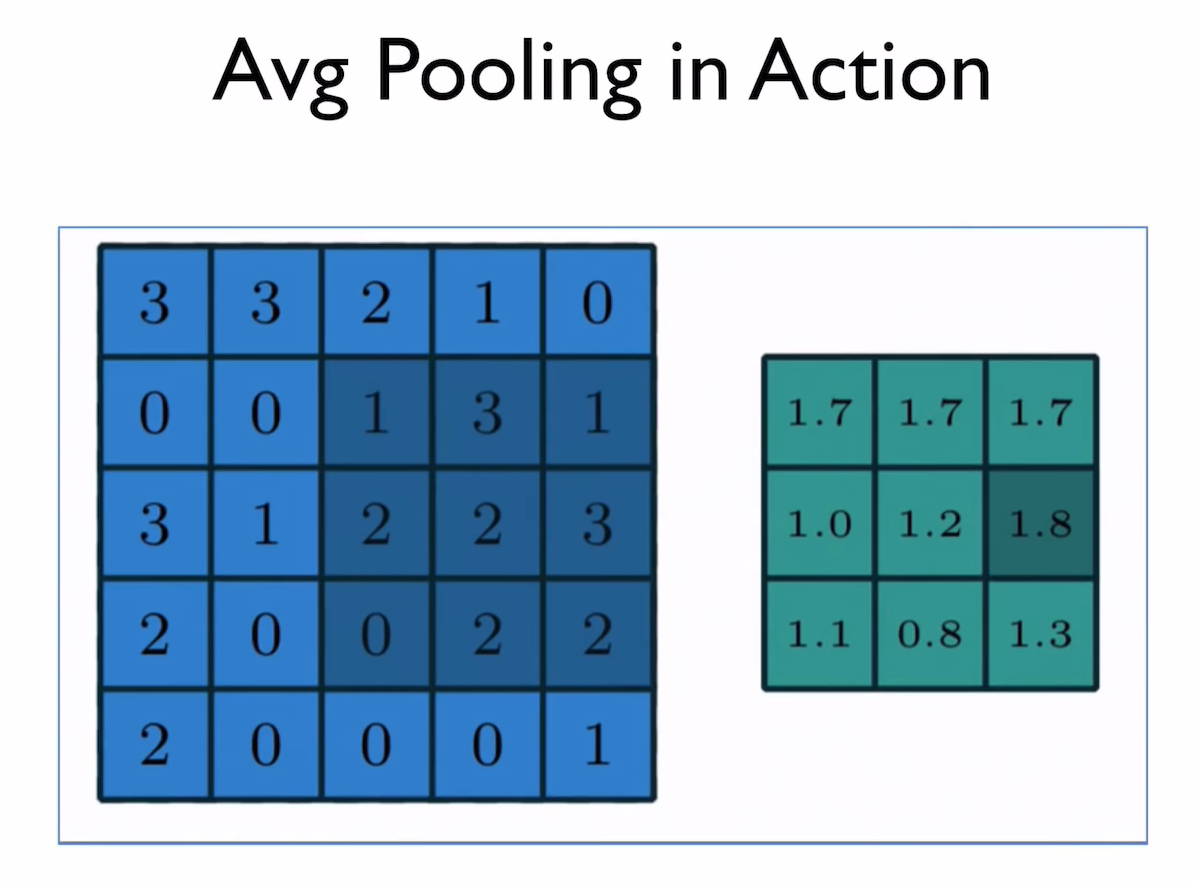
추출된 특징(activation map)들을 필요에 따라 서브 샘플링(Sub-sampling) 과정을 거치게 되는데 이를 pooling이라고도 부른다.
컨볼루션 과정을 통해 특성이 계산되었지만 이를 모두 사용하지 않고, 특징 맵을 줄이는 작업을 수행하는데 이를 Pooling이라 한다.
풀링연산 자체가 인접픽셀을 대상으로 진행되기 때문에 입력 데이터가 조금 변형되더라도(이미지의 이동, 회전 등) 해당 풀링은 크게 변하지 않는다. 따라서 어떤 특징의 위치가 아닌 존재여부만을 판단할 때는 이러한 풀링 연산의 특성이 유용하다.

Pooling의 가장 큰 이점 중 하나는 데이터의 차원 감소이다.
풀링을 통해 전체 데이터 크기가 줄어들기 때문에 연산량이 적어지고,
데이터 크기를 줄이면서 소실이 일부 발생하기 때문에 오버 피팅을 방지 할 수 있는 효과가 있다.
(동시에 차원의 축소로 인해 더 자세한 edge 정보를 동일한 필터 size로도 살펴볼수 있게 되었다, 더 풀어서 얘기하면 우리가 관찰해야할 영역이 확대되어 동일한 필터로도 더 자세한 영역을 볼수 있다고 할 수 있을 것이다)
물론 위에서 말햇듯이 Stride를 통한 Conv 계산만으로도 차원축소 효과가 있다. 하지만 pooling을 통해 이를 한번 더 축소한다라고 생각하면 된다.
이 중 Max pooling은 feature map을 M x N 크기로 잘라낸 후, 그 안에서 가장 큰 값을 뽑아내는 방법이다.
추가)
몇몇 논문들을 보면 VGG까지는 Max pooling을 많이 사용했으나, 이후 Max pooling으로 차원을 감소하지 않고, 컨볼루션 필터의 스트라이드를 늘리는것으로 차원축소를 하는 연구방향들이 추가되었다. 이는 ResNet이나 GoogleNet에서 좀더 깊은 망을 실현시키기 위해 처음 도입했다. Max Pooling으로 일정 영역의 강한 feature만을 다음 레이어로 넘기면, 처음에는 계산량을 크게 줄여 좋은 성능을 유지할 수 있을지 몰라도, 매우 Deep한 신경망으로 가면 갈수록, 점점 더 미세한 feature가 중요해지는데, 해당 정보가 날아가기 때문에 컨볼루션 연산을 수행해서 스트라이드를 늘리는 방식으로 차원을 축소한다. 이를 통해서 feature를 버리는게 아니라, feature에 대해서 컨볼루션 연산을 수행해서 해당 feature를 고려할 수 있기 때문에 deep한 망으로 가면 갈 수록 이점을 살린다고 한다.
-- 결국 계산 복잡성과 성능 사이의 벨런싱 문제인듯 하다
Fully Connected Layer
최종 ConvNet의 모양은 다음과 같이 구성된다.
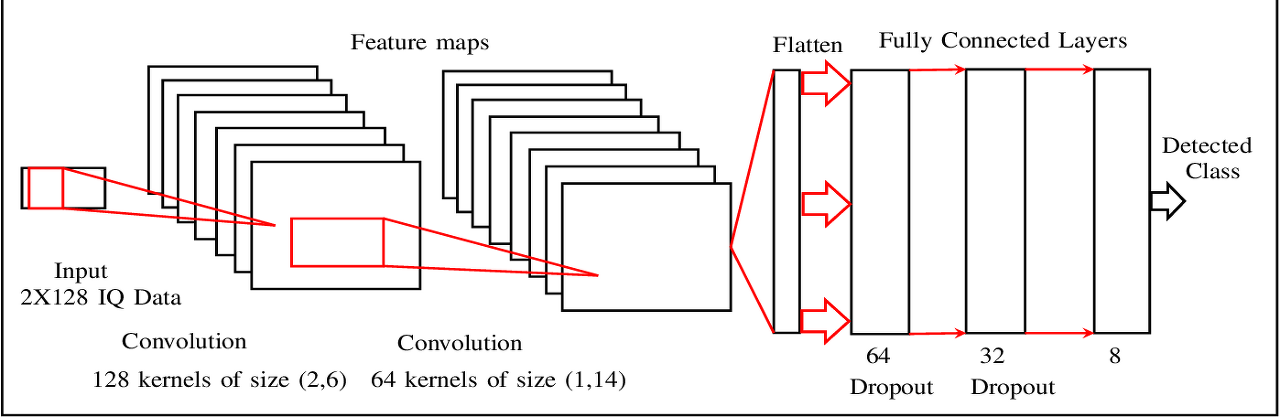
structure of cnn 컨볼루션 계층에서 특징이 추출되었으면 이 추출된 특징 값을 기존의 신경망에 적용하여
분류하는 과정을 거친다. 이 때 분류를 위해 Softmax함수가 사용된다(이미지 또한 multi class로 분류하는 문제이기 때문)
추가적으로 최종적으로 softmax함수를 거치기 전에 Dropout기법이 사용된다.
드롭아웃(Dropout)
드롭아웃 기법은 오버피팅을 막기 위한 방법으로,
신경망이 학습중 일 때 랜덤하게 뉴런을 드롭아웃 시켜 뉴런간 연결을 일부 끊어버린다. 이때 이는 오로지 랜덤하게 drop-out rate으로 결정된다(하이퍼 파라리미터로 일반적으로 0.5로 설정)
이를 통해 특정한 설명 feature 변수에만 집중되어 학습하는 것을 막아 overfitting을 막는다.
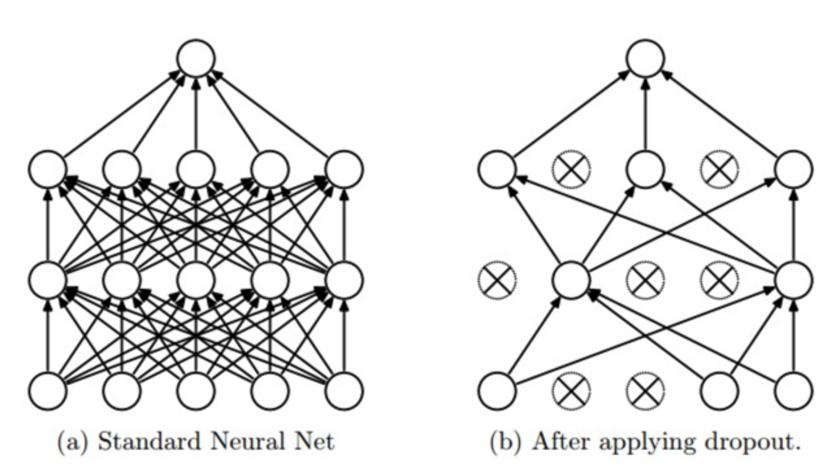

Dropout 이미지와 Dropout 적용위치 드롭아웃의 위치는 hidden unit에 적용하면 된다고 한다.
https://arxiv.org/abs/1207.0580
Improving neural networks by preventing co-adaptation of feature detectors
When a large feedforward neural network is trained on a small training set, it typically performs poorly on held-out test data. This "overfitting" is greatly reduced by randomly omitting half of the feature detectors on each training case. This prevents co
arxiv.org
Code Implement(using MNIST data)
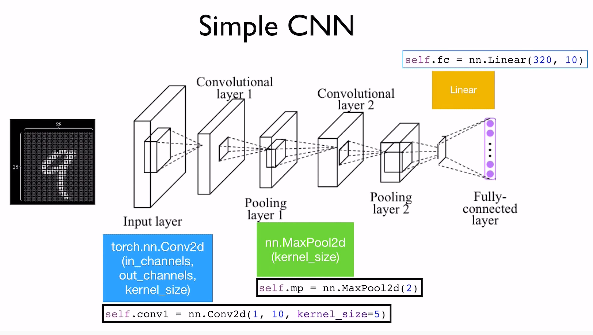
위의 이미지와 같이 MNIST 데이터를 CNN을 이용하여 분류해보자.
동일한 링크에 코드를 작성하였다.
https://colab.research.google.com/drive/1QB72fSRQTZihbzbp8qf7cf-jRWZFy4Ax#scrollTo=Ro8BiceffzUz
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
코드를 보면 이번에는 conv layer를 2개 이용한 뒤 max pooling을 함을 볼 수 있다.
이때 차원의 수에 유의하자.
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=3) #kernel size는 임의로 결정 self.conv2 = nn.Conv2d(10, 20, kernel_size=3) self.mp = nn.MaxPool2d(2) #filter의 수 동시에 얼마나 사이즈를 비교할 것인지 결정 self.fc = nn.Linear(500, 10) #Linear에서 받는 차원의 수는 돌려보면 에러로 나옴, 물론 직접 계산도 가능 def forward(self, x): in_size = x.size(0) x = F.relu(self.mp(self.conv1(x))) x = F.relu(self.mp(self.conv2(x))) x = x.view(in_size, -1) #-1은 torch에게 조작 맡김 x = self.fc(x) return F.log_softmax(x)아래 코드는 동일하지만 dropout을 적용한 예시이다.
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=3) self.conv2 = nn.Conv2d(10, 20, kernel_size=3) self.mp = nn.MaxPool2d(2) self.fc = nn.Linear(500, 10) self.dropout = nn.Dropout(0.5) #dropout 추가 def forward(self, x): in_size = x.size(0) x = self.mp(F.relu(self.conv1(x))) x = self.mp(F.relu(self.conv2(x))) x = x.view(in_size, -1) #-1은 torch에게 조작 맡김 x = self.fc(x) x = self.dropout(x) return F.log_softmax(x)Dropout을 사용할 때 주의할 점
.... def train(epoch): model.train() #dropout True for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) ... def test(): model.eval() #dropout False test_loss = 0 correct = 0 .....
- model.train()
(Trian mode) 학습할 땐 무작위로 노드를 선택하여 선별적으로 노드를 활용함 - model.eval()
(Evalutaion mode) 평가하는 과정에서는 모든 노드를 사용하겠다는 의미
model.train()과 model.eval()을 꼭 선언을 해야지 모델의 정확도를 높일 수 있다.BatchNorm에서도 사용한다.
자세한 내용은 파이토치 공식문서를 확인해보자.
이후 실행 코드는 이전과 동일하다.
from __future__ import print_function import torch from torch import nn, optim, cuda from torch.utils import data from torchvision import datasets, transforms import torch.nn.functional as F import time # Training settings batch_size = 64 device = 'cuda' if cuda.is_available() else 'cpu' print(f'Training MNIST Model on {device}\n{"=" * 44}') # MNIST Dataset train_dataset = datasets.MNIST(root='./mnist_data/', train=True, transform=transforms.ToTensor(), download=True) test_dataset = datasets.MNIST(root='./mnist_data/', train=False, transform=transforms.ToTensor()) # Data Loader (Input Pipeline) train_loader = data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) model = Net() model.to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) def train(epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() if batch_idx % 10 == 0: print('Train Epoch: {} | Batch Status: {}/{} ({:.0f}%) | Loss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) def test(): model.eval() test_loss = 0 correct = 0 for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) # sum up batch loss test_loss += criterion(output, target).item() # get the index of the max pred = output.data.max(1, keepdim=True)[1] correct += pred.eq(target.data.view_as(pred)).cpu().sum() test_loss /= len(test_loader.dataset) print(f'===========================\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ' f'({100. * correct / len(test_loader.dataset):.0f}%)') if __name__ == '__main__': since = time.time() for epoch in range(1, 10): epoch_start = time.time() train(epoch) m, s = divmod(time.time() - epoch_start, 60) print(f'Training time: {m:.0f}m {s:.0f}s') test() m, s = divmod(time.time() - epoch_start, 60) print(f'Testing time: {m:.0f}m {s:.0f}s') m, s = divmod(time.time() - since, 60) print(f'Total Time: {m:.0f}m {s:.0f}s\nModel was trained on {device}!')결과는 각각 아래와 같다.
Test set: Average loss: 0.0011, Accuracy: 9774/10000 (98%) Testing time: 0m 16s Total Time: 2m 24s Model was trained on cpu!
Test set: Average loss: 0.0011, Accuracy: 9810/10000 (98%) Testing time: 0m 16s Total Time: 2m 27s Model was trained on cpu!
정확도는 개선되었지만 생각보다 엄청난 차이가 있지는 않았다..! MNIST dataset이 워낙 분류가 잘 되어있는 모델이라 그런거일 수도 있다는 생각을 한다.
'ML&DL 이야기 > Pytroch' 카테고리의 다른 글
- model.train()