-
[금융공학개론(INE3083)]Portfolio Management Project using Markowitz Model and Time series(Using RNN, LSTM, GRU)전공&대외활동 이야기/전공 프로젝트 모음 2023. 11. 8. 22:37
목적 및 dataset
제공된 dataset.csv 파일에는 KOSPI & KOSDAQ의 1999-12-28 ~ 2020-12-30일 까지의 주식 종목들의 montly retrun data가 있다. 이를 이용하여 montly-rebalanced protfolio를 만들고 이에 따른 backtesting을 진행해라(제공된 dataset 파일은 학교에서 제공된 파일이라 따로 업로드하지 못했습니다)
참고한 자료
원자재 시장에서의 마코위츠 포트폴리오 선정 모형의 투자 성과 분석(김승현, 김성문 2013) 자료 및 About a few solvers for Markowitz portfolio selection problem(Bogusz Jelinski 2016) 자료를 참고하여 코드를 작성하였다.
프로젝트 개요
1. 마코위츠 모델을 포트폴리오 최적화 모델로 선정, 리벨런싱 주기는 1달로 설정한다
2. 마코위츠 모델에 들어가는 N개의 종목 선정의 경우,
1) 종목선정이 모델에 주는 영향을 최소화하고 2) 전체 시장지수 데이터(KOSPI)와 비교하기 위해
종목선정을 진행하지는 않는다.
3. 마코위츠 모델의 경우 r의 expectation value로 평균을 사용하지만, 이를 시계열 모델을 이용해 추정한 값으로 변경했을 때 모델의 성능이 얼마나 변하는지 확인할 것이다.
4. 모델의 Train은 2000~2010년도 까지 진행하며, 성능평가는 2010~2020년까지의 데이터를 이용한다. 이 때 backtesting을 진행함에 있어, Walking Foward 방법을 이용한다.
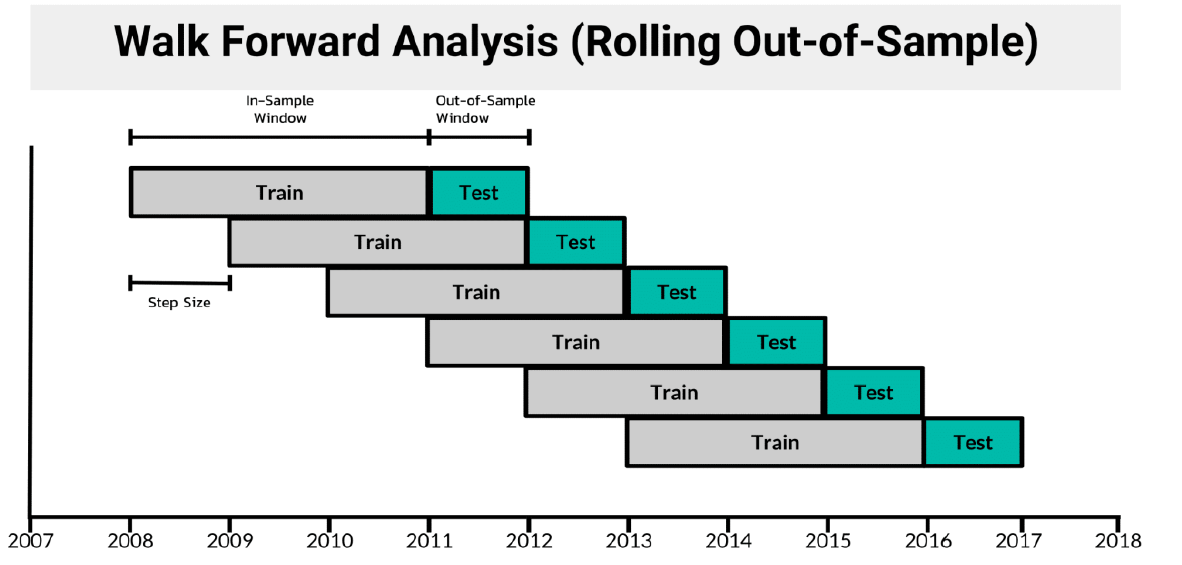
walking forward 5. 최종적인 모델의 성능은 Cumulative Return, Sharpe ratio, Annualized return, Annualized risk를 이용해 평가한다.
Markowitz Model

Markowitz Model https://en.wikipedia.org/wiki/Markowitz_model
마코위츠 모델은 1952년 Harry Markowitz가 제시하나 모델로, 포트폴리오의 risk를 수익변동성, 즉, standard deviation으로 취급하며, 이를 minimize하는 포트폴리오를 찾는 것을 목적으로 한다.
w는 포트폴리오를 구성하는 금융자산의 가중치이며 이들의 총합은 1이다.
각 가중치가 0보다 크다라는 조건을 사용하는 것은, 공매도를 허용하지 않는 조건에 해당한다.
s.t의 첫번째 식에 r은 목표하는 수익률로, 보통 주어진다.
이는 대다수의 경우 미국의 3년물 국채를 이용하는 경우가 대다수이다(3 year treasury bonds)
Code Implementation
프로그램 전체 코드는 아래와 같다.
https://colab.research.google.com/drive/1TJbQ9JZAKbfmE6AjGw8htgq6PNhiGUDm?usp=sharing
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
성과표는 아래와 같다
https://drive.google.com/file/d/1JpHE7ZcdaITTuisgSJ02NPjj9khO7xPI/view?usp=sharing
Performance_Metric.xlsx
drive.google.com
Data Preprocessing
우선 한국시장을 대상으로 하기에 한국 국채 3년물을 기준으로 최소 목표를 잡았다.
이때 우리는 1달을 주기로 리벨런싱을 하기에 1년 수익율을 1달로 변경하였다
KTB data는 :https://ecos.bok.or.kr/#/StatisticsByTheme/KoreanStat100, 한국 은행 경제통계 시스템에서 가져왔다
1. 가격 데이터를 rate of return(수익률)로 변경

원본데이터 원본 데이터는 위와 같이 각 달 주식의 시작가, 종가가 적힌 데이터이다.
그럼으로 이를 아래 코드를 이용해 같이 수익율 데이터로 변형하였다.
# 각 주식의 수익율을 계산하여 새로운 데이터프레임에 추가 for column in df.columns: current_prices = df[column].values previous_prices = df[column].shift(1).values # 이전 달의 가격 returns = (current_prices[1:] - previous_prices[1:]) / previous_prices[1:] # 수익율 계산 returns_df[column] = returns # 결과 출력 returns_df
수익율 데이터 이후 한국 국채를 기준으로 한 risk free column을 데이터프레임에 추가하는 것으로 데이터 처리를 마무리했다(추가적인 날짜 index를 달로 변경하는 부분은 단순히 문자열 slicing을 통해 해결하였다)

최종 dataframe Markowitz Model
마코위츠 모델의 해를 구하기 위해서는 LP문제를 풀어야하는데(공매도 금지 조건임), 이는 cvxopt를 이용하여 해결하였다. 코드 예시는 아래와 같다

마코위츠 모델의 해를 구하는 법 우리는 이를 이용해 1) 포트폴리오의 수익율을 구해야하고 2) r_min이 고정되어있지 않고, 각 달별로 변화하기 때문에(정확히는 연이다, 국채를 기준으로 변동하기에) 코드를 아래와 같이 변형하였다.
우선 계산된 가중치 값을 담을 md_df와 , 포트폴리오의 수익율을 기록한 result dataframe을 만든다. 그 결과는 아래와 같다
#result is from 2010~2020 # Initialize an new dataframe for makwowitz weight(so except risk free) mk_df = pd.DataFrame(df.iloc[120:][:]) #result of protfolio(so use mk_df and date for r) result = pd.DataFrame() result['date'] = df.iloc[120:]['date'] result['r'] = None result.reset_index(drop=True, inplace=True) #md_df mk_df.drop(['risk_free'], axis=1, inplace= True) mk_df.reset_index(drop=True, inplace=True) mk_df.iloc[:,1:] = 0 mk_df

좌측 이미지가 result, 우측이 mk_df이다 이후 우리는 10년치 데이터를 historical data로 두고 마코위츠 모델을 돌리기 때문에 window size를 120(12달 * 10년)으로 잡고 for문을 돌린다.
이 때 for문의 반복횟수는 133번이다(전체 데이터가 252 행, 252-120+1=133(132+1))
#code ver2 # Iterate through the dataframe using a sliding window for i in range(len(df) - window_size): #sliding window for i window = stock_df.iloc[i:i + window_size, :] # Perform computations on the window n=window.shape[1]-1 r_min = df.iloc[i+window_size][1] Cov = matrix(window.cov().to_numpy()) Mean = matrix(window.mean().to_numpy()) G = matrix(np.concatenate((-np.transpose(Mean), -np.identity(n)), 0)) h = matrix(np.concatenate((-np.ones((1,1))*r_min, np.zeros((n,1))), 0)) A = matrix(1.0, (1,n)) b = matrix(1.0) q = matrix(np.zeros((n, 1))) sol = qp(Cov, q, G, h, A, b) w = np.asarray(np.squeeze(np.asarray(sol['x']))) mk_df.iloc[i, 1:] = w result.loc[i, 'r'] = w.dot(df.iloc[i+window_size][2:].transpose())for문을 해석하면 window는 우리가 참고할 historical dataset으로 10년치 dataset에 해당하는 dataframe이다.
또한 r_min 현재 목표하고자하는(과거가 아닌 현재) r_min이기에 + 1하는 크기만큼 더 간다(하지만 행은 0부터 시작하기에 그냥 i+windowsize면 충분)
이후 계산식은 cvxopt를 통해 계산하고, 결과는 mk_df에 입력하고,
수익율 또한 각 주식의 계산하고자 하는 수익율이 r_min과 동일한 부분에 위치하기에 이를 마코위츠에서 계산된 가중치와 내적하여 구한다.
최종적으로 결과값을 저장한다
result.to_csv("result_markowitz.csv", index=None, mode='w')RNN And Markowitz Model
기존 Markowitz에서는 mean을 이용해 r의 예측값(기댓값?)을 구하였다.
이를 시계열을 이용한 추정으로 변형해보자. 시계열 추정에 RNN모델을 이용하였다
from cvxopt import matrix from cvxopt.solvers import qp import numpy as np import pandas as pd import numpy as np import matplotlib.pyplot as plt import torch import torchvision.transforms as transforms import torchvision.datasets from torch.autograd import Variable from torch.nn import Parameter from torch import optim, cuda, Tensor import torch.nn as nn from torch.utils import data from torch.utils.data import Dataset, DataLoader import torch.nn.functional as F import time import copy import matplotlib.pyplot as plt import math from datetime import datetime from sklearn.preprocessing import MinMaxScaler, MaxAbsScaler plt.style.use('seaborn-whitegrid')빠른 연산을 위해 gpu를 사용하자
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') cuda = True if torch.cuda.is_available() else False Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor torch.manual_seed(125) if torch.cuda.is_available() : torch.cuda.manual_seed_all(125)새롭게 결과값을 구할 데이터프레임 정의
#result is from 2010~2020 # Initialize an new dataframe for makwowitz weight(so except risk free) mk_df = pd.DataFrame(df.iloc[120:][:]) #result of protfolio(so use mk_df and date for r) result = pd.DataFrame() result['date'] = df.iloc[120:]['date'] result['r'] = None result.reset_index(drop=True, inplace=True) #md_df mk_df.drop(['risk_free'], axis=1, inplace= True) mk_df.reset_index(drop=True, inplace=True) mk_df.iloc[:,1:] = 0 mk_dfrisk min을 뺀 stock df를 정의한다(계산의 편의성을 위해)
stock_df = df.drop(['risk_free'],axis=1, inplace=False)sequential 데이터로 변형해줄 부분을 추가(RNN이기에)
def seq_data(time_series, seq_length): dataX = [] dataY = [] for i in range(0, len(time_series)-seq_length): _x = time_series[i:i+seq_length, :] _y = time_series[i+seq_length, [-1]] # print(_x, "-->",_y) dataX.append(_x) dataY.append(_y) return np.array(dataX), np.array(dataY) #x,y의 seq데이터를 반환Pytorch를 이용해 RNN Class 정의
class RNN(nn.Module): def __init__(self, input_dim, hidden_dim, seq_length, num_layers, output_dim, device): super(RNN, self).__init__() self.device = device self.hidden_dim = hidden_dim self.seq_length = seq_length self.num_layers = num_layers self.output_dim = output_dim self.rnn = nn.RNN(input_dim, hidden_dim, num_layers, batch_first=True) self.fc = nn.Linear(hidden_dim * seq_length, output_dim) def forward(self, x): hx = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(self.device) #hidden 초기값 0으로 설정 out,_ = self.rnn(x, hx) out = out.reshape(out.shape[0], -1) # many to many out = self.fc(out) return outRNN 학습에 관한 코드를 따로 정의한다(향후 마코위츠에 적용하기 위해, 학습된 모델이 따로 필요하다)
def train_model(model, train_df, num_epochs = 200, lr = 1e-3, verbose = 10, patience = 10): criterion = nn.MSELoss().to(device) optimizer = optim.Adam(model.parameters(), lr = lr) nb_epochs = num_epochs # epoch마다 loss 저장 train_hist = np.zeros(nb_epochs) for epoch in range(nb_epochs): avg_cost = 0 total_batch = len(train_df) for batch_idx, samples in enumerate(train_df): x_train, y_train = samples outputs = model(x_train) # cost 계산 loss = criterion(outputs, y_train) # cost로 H(x) 개선 optimizer.zero_grad() loss.backward() optimizer.step() avg_cost += loss/total_batch train_hist[epoch] = avg_cost if epoch % verbose == 0: print('Epoch:', '%04d' % (epoch), 'train loss :', '{:.4f}'.format(avg_cost)) # patience번째 마다 early stopping 여부 확인 if (epoch % patience == 0) & (epoch != 0): # loss가 커졌다면 early stop if train_hist[epoch-patience] < train_hist[epoch]: print('\n Early Stopping') break return model.eval(), train_histRNN을 이용해 예측된 r을 구하는 함수를 정의한다.
def rbyRNN(window, i, df): seq_length=9 size = window_size #to split train data and test data #df except date #train_df가 window가 되어야함! train_df = window.iloc[:, 1:] test_df = df.iloc[i+window_size-seq_length:,2:] train_data = train_df.values test_data = test_df.values x_train_seq, y_train_seq = seq_data(train_data, seq_length) x_test_seq, y_test_seq = seq_data(test_data, seq_length) x_train_seq = torch.FloatTensor(x_train_seq).to(device) y_train_seq = torch.FloatTensor(y_train_seq).to(device) x_test_seq = torch.FloatTensor(x_test_seq).to(device) y_test_seq = torch.FloatTensor(y_test_seq).to(device) train = torch.utils.data.TensorDataset(x_train_seq, y_train_seq) test = torch.utils.data.TensorDataset(x_test_seq, y_test_seq) batch_size = 100 train_loader = torch.utils.data.DataLoader(dataset=train, batch_size = batch_size, shuffle=False) #testloader는 1개만 필요 test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=1, shuffle=False) #for model data_dim = x_train_seq.size(2) #664 hidden_dim = 664 #just direct hidden_dim output_dim = x_train_seq.size(2) #for all stocks num_layers = 2 model = RNN(input_dim=data_dim, hidden_dim = hidden_dim, seq_length=seq_length, num_layers=num_layers, output_dim=output_dim, device=device).to(device) e_model, train_hist = train_model(model, train_loader, num_epochs = 200, lr = 1e-3, verbose = 20, patience = 10) e_model.eval() pred = [] with torch.no_grad(): for batch_idx, samples in enumerate(test_loader): x, y = samples outputs = e_model(x) pred.append(outputs) break l_pred=pred[0][0].tolist() return np.array(l_pred)최종적으로 Markowitz 모델을 돌려보자.
#code for RNN # Iterate through the dataframe using a sliding window for i in range(len(df) - window_size): #sliding window for i window = stock_df.iloc[i:i + window_size, :] # Perform computations on the window n=window.shape[1]-1 r_min = df.iloc[i+window_size][1] Cov = matrix(window.cov().to_numpy()) #change Mean to RNN predict Mean = matrix(rbyRNN(window, i, df)) G = matrix(np.concatenate((-np.transpose(Mean), -np.identity(n)), 0)) h = matrix(np.concatenate((-np.ones((1,1))*r_min, np.zeros((n,1))), 0)) A = matrix(1.0, (1,n)) b = matrix(1.0) q = matrix(np.zeros((n, 1))) sol = qp(Cov, q, G, h, A, b) w = np.asarray(np.squeeze(np.asarray(sol['x']))) mk_df.iloc[i, 1:] = w result.loc[i, 'r'] = w.dot(df.iloc[i+window_size, 2:].transpose())LSTM & GRU
동일한 방법으로 LSTM과 GRU에 관해서도 학습이 가능하다
다만, Markowitz 식의 해를 구하는 과정에서 inf 에러, domain에러가 발생하는데 r은 예측하는것은 큰 문제가 없는 것 같지만, LP문제를 푸는데 문제가 있는 것 같다
결과(excel 참고)


예상했지만, Time series를 이용한 모델이 가장 성능이 좋게 나왔다. 또 그 지표차이가 굉장히 커서(누적 수익율 기준 거의 기존 Markowitz보다 2배) 놀라운 결과였다
물론, 이는 여러가지 이상적인 가정(dataset, 이상적인 연도들)하에 이루어진 backtesting이기에 완전히 신뢰해서는 안되겠지만, 여전히 유의미한 결과를 보여주었다
다른 시계열 모델들에 관해서도 성능 및 지표를 확인해보고, 비교해보면 좋을 것 같다
'전공&대외활동 이야기 > 전공 프로젝트 모음' 카테고리의 다른 글
[TAF] 시계열 Air Passenger Forcasting Project (0) 2024.07.01 [Applied Data Analytics] Pickle? CSV? 데이터 파일의 형식에 관해 (0) 2024.03.31