-
[NLP] RNN, LSTM과 NLP 개론ML&DL 이야기/ML 2024. 2. 13. 20:46
허민석님의 자연어처리 유튜브 재생목록(https://youtu.be/meEchvkdB1U?si=KHEXvalYlF_RlkE9)과
LgAimers의 주재걸 교수님의 seq2seq with Attention 강의, 나동빈님의 seq2seq 영상을 바탕으로 작성하였습니다.Natural Lenguage = Sequence Data

sequence의 정의: Naver 영어사전 출처 우리는 자연어, 즉, 문장을 말할때, 문장은 단어의 연속된 집합으로 들어온다. 즉, 순차적인 단어의 구성이 바로 문장이다.
즉, 문장은 가장 최신의 과거 데이터(단어)를 바탕으로 업데이트 되는 시계열적인 특성을 지닌다.
이 점에서 sequence data라고 할 수 있을 것이다.
전통적인 NN의 경우 이러한 지속성을 지니는 데이터를 처리하기에 어려움이 있었는데, 이는 입력값들을 서로 독립적이라고 가정했기 때문이다(IID 가정).
결국, 자연어처리를 위해서는 연속적인 데이터를 처리하기 위한 새로운 아키택쳐(서로가 서로의 상태에 영향을 끼치는)가 필요하고, 그것이 바로 Recurrent neural network, RNN이다.
자연어 처리의 대표적인 아키텍쳐들의 역사는 아래와 같다.

출처: https://youtu.be/4DzKM0vgG1Y?si=GrjYvVq5OrRHSPVC, 동빈나 유튜브 이때 Attention 기법과 Transformer 이후로 대다수의 NLP 모델이 Transformer 기반의 아키택쳐를 취하고 있으나, 그전의 SOTA 모델은 거의 Seq2Seq기반이었다.
이는 앞서 말한 RNN 모델을 변형시킨 것이기에 그 흐름에 맞추어 하나씩 모델들을 살펴보려고 한다.
RNN(Recurrent Neural Network)
RNN 모델은, 앞서 말한 것처럼 과거(기존)의 State, 혹은 data를 현재의 input과 결합시켜서 학습하는 것이 목표이다.

수식을 살펴보면, 새로운 state를 얻음에 있어서, 직전의 state와 새로운 input을 모두 Input으로 사용하여 Fully connected layer와 Activation layer을 통과시키는 것을 확인 가능하다. 이후, output이 필요하다면 Output layer를 통과시킨다.
이 때 RNN의 경우 Activation funtion으로 tanh을 이용한다.
RNN을 시간단위로 펼쳐보면 아래와 같은 모델일 것이다.
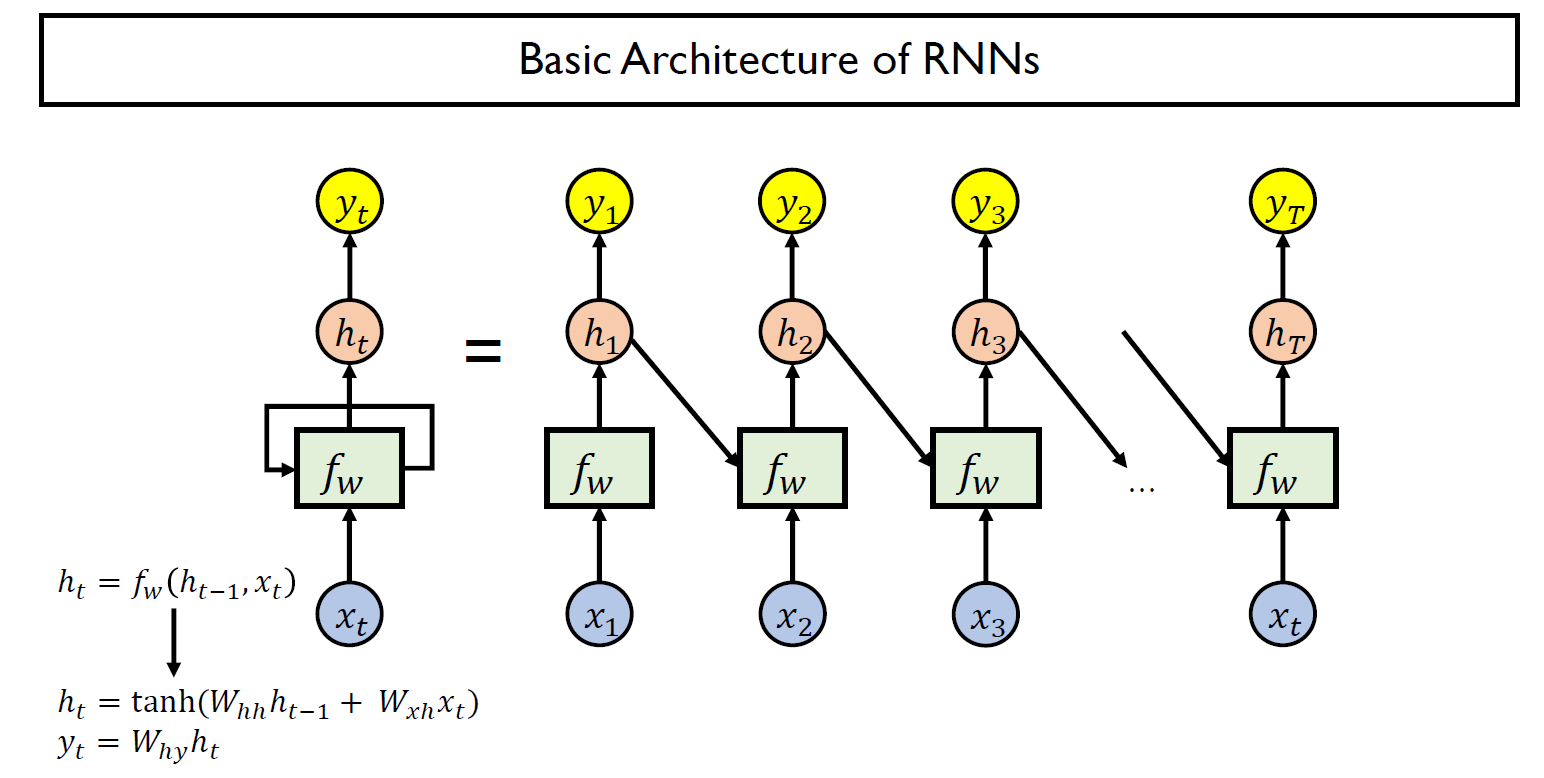
이때, $h_(t-1)$과 $x_t$의 차원을 잘 맞추어 줘야한다. 정확히는 Fully connected layer를 통과한 X의 ouptput과 h의 ouput의 차원이 동일할 것이다(그래야 합산을 통해 activation function을 통과함)
추가적으로 만일 output이 필요한 경우 해당 차원을 원하는 output을 위해 선형변환을 해주는 layer, 즉, output layer가 해당부분에 필요하다.
Various problem settings of RNN-based Sequence Modeling
위에서 밝힌 것 처럼, output layer을 어디에 추가하느냐에 따라서 우리는 다양한 형태의 결과들을 도출해내는 모델을 만들 수 있다. 즉, 여러 상황에 맞게 problem setting이 가능하다.
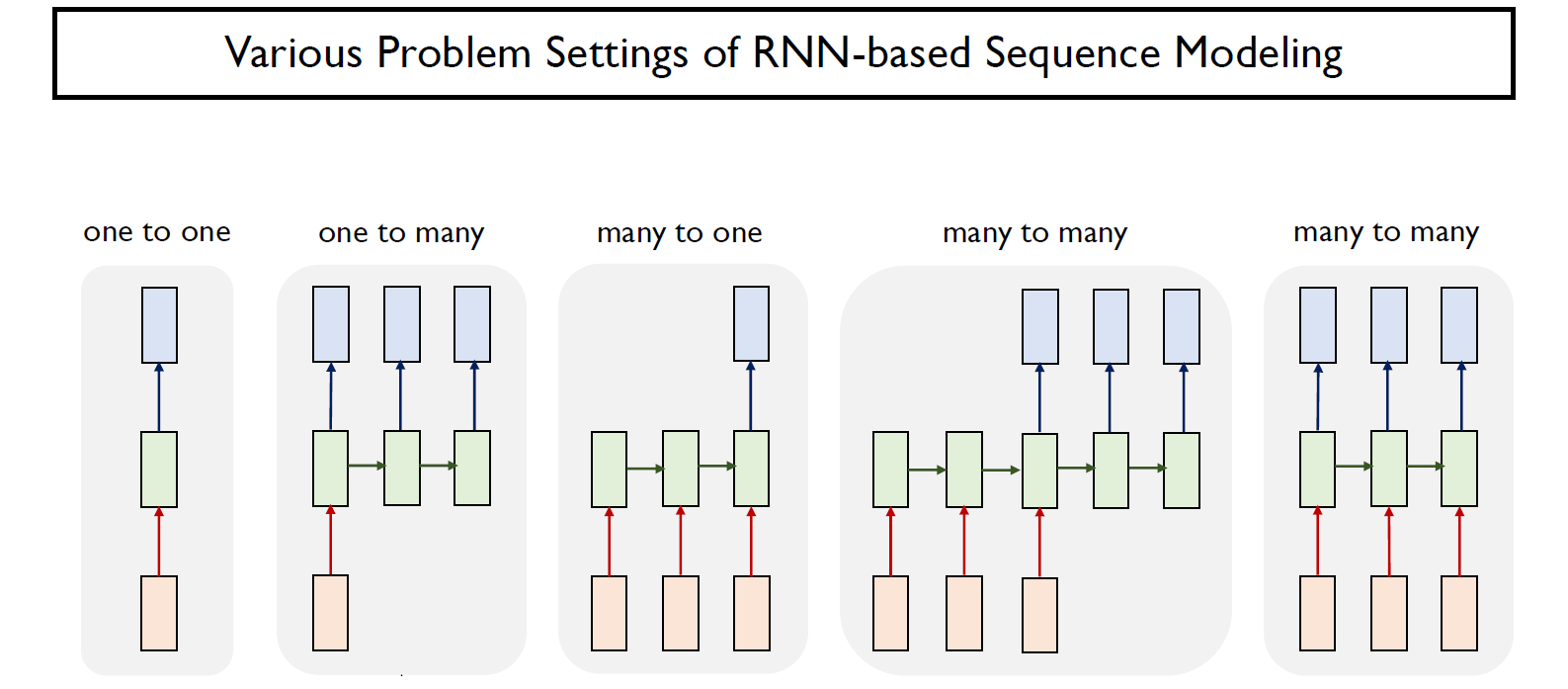
가령, One to many의 경우 Image captioning에 사용가능할 것이다. 이는 그림을 inpupt으로 받아 output으로 해당 그림을 설명하는 문장을 출력하는 모델일 것이다. 즉, 전체이미지가 주어졌을때 sequence로 예측해주는 형태를 띄게된다.
또한 Many to one의 경우 문장 분류 task에 사용될 것이다. 즉, 어떤 sequence data, 문장이 주어졌을 때, 이것이 긍정적인지 부정적인지를 판단하는 task를 말한다.
Many to Many의 경우 기계번역 task에 사용되며, seq2seq의 기본적인 형태라고 볼 수 있다.
또한 가장 우측의 모델의 경우, 예측 결과물을 실시간으로 출력하는 형태로 비디오를 실시간으로 프레임별로 결과를 뽑아내는 등, dalay를 허용하지 않는 문제에 사용 가능할 것이다.
Example: character level languaege model
가장 기본적인 형태로, hello를 예측하는 모델을 예시로 들어보자.
우선 Input으로는 one-hot encoding형태로 hello의 각 character level로 입력해준다(가장 기본적인 input방법으로 추가적으로 n-gram이나 word2vec이용 가능)

이후 우리는 각 character별로 다음 character를 예측하려는 것이 목적임으로, output layer를 softmax로 모든 층에 둔다. 이후 오차의 경우 Cross entropy loss를 적용해서 update하는 것이 가능할 것이다.
중요한 것은 test-time에서는 단순히 1 character를 예측하는 것이 아니라, 하나의 input만 주어도 이후 연속된 character를 연속적으로 예측하는(즉, 모델이 예측한 데이터를 다음 input으로 주는) 방법으로 확인한다. 이것을 auto-regressive model이라고 한다.
Long Short-Term Memory(LSTM)
Vanilla RNN의 경우 gradient vanishing 혹은 exploding 문제가 생기는 경우가 생겨 학습이 불안정해지는 문제가 생겼다. 이는 긴 시퀸스에 대해 훈련하면서 동일한 가중치를 반복적으로 이용함에 따라 생기는 부작용이다.
https://stats.stackexchange.com/questions/140537/why-do-rnns-have-a-tendency-to-suffer-from-vanishing-exploding-gradient
1. An unrolled RNN tends to be a very deep network.
2. In an unrolled RNN the gradient in an early layer is a product that (also) contains many instances of the same term.이를 해결하기 위해 LSTM혹은 GRU을 이후에 이용하기 시작하는데,
기본적인 setting자체는 그대로 가져가지만, 그 안의 RNN cell에 해당하는 부분이 변형된 형태이다.
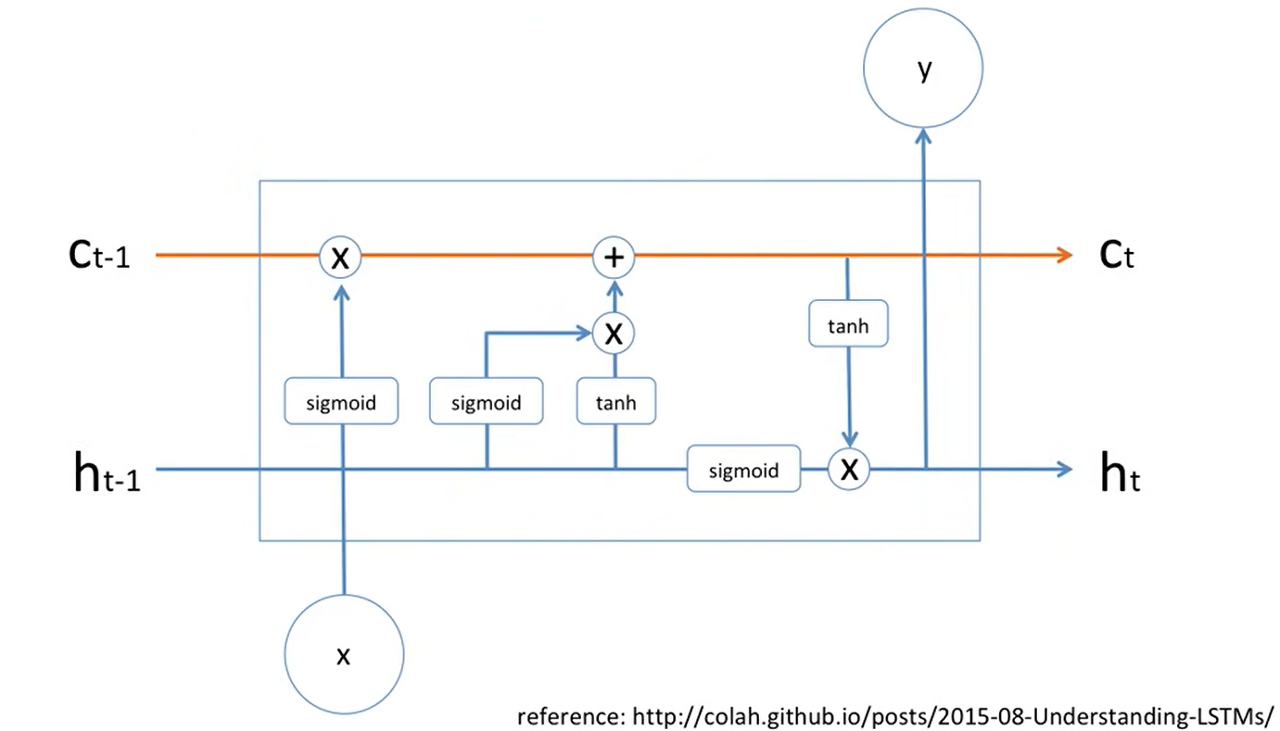
LSTM의 Cell구조 즉, LSTM은 위의 문제를 해결하기 위해 gate구조를 추가하였다.
LSTM 셀에서는 상태(state)가 크게 두 개의 벡터로 나누어지며 를 단기 상태(short-term state), 를 장기 상태(long-term state)라고 한다.
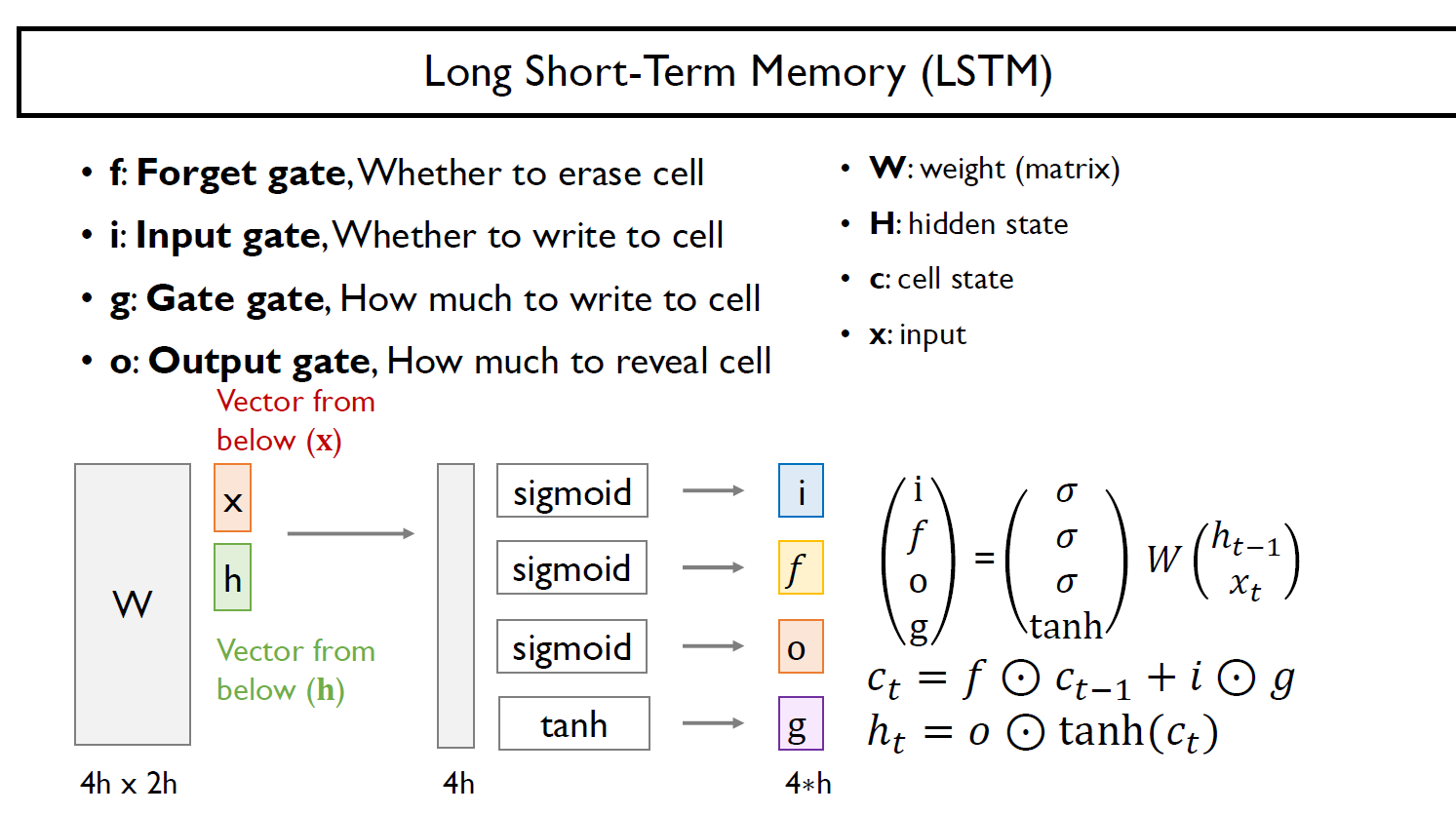
ㄱ 각 정보는 f, i, g, o 이렇게 4개의 gate를 통과하는데 각각의 gate에 관한 자세한 설명은 기존에 블로그 링크를 첨부한다.
https://secundo.tistory.com/46
LSTM(Long short term memory)
LSTM이 나오게 된 배경 RNN의 경우 상태와 현재 상태의 거리가 멀어질 경우 vanishing(exploding) gradient problem(거리가 멀 수록 gradient가 크게 줄어(증가) 학습에 영향을 주지 못하는 상태), 장기 의존성 문
secundo.tistory.com
'ML&DL 이야기 > ML' 카테고리의 다른 글
[NLP] BLEU Score(Bilingual Language Evaluation Understudy) (0) 2024.02.16 Beam Search in NLP (1) 2024.02.16 [ML] Convolution 합성곱의 정의와 FFT 고속푸리에 변환에 관하여 (1) 2023.10.08 [ML] Regression과 Logit(승수)와 Sigmoid함수 그리고 Softmax함수 (0) 2023.10.02 [ML] Entropy와 Negative log likelihood(NLL) (1) 2023.10.02