-
Beam Search in NLPML&DL 이야기/ML 2024. 2. 16. 16:46
Text 생성을 위한 Decoder에서 우리는 단어들을 연속적으로 생성하는 task를 수행해야한다(sequence data).
모델의 출력은 확률적으로 가장 가능성이 높은 확률을 띄는 조합의 단어 조합으로 결정된다.
즉, 언어 모델은 단어 시퀀스에 확률을 할당하는 모델이며, Decoder의 경우 다음에 나올 확률이 최대인 단어를 선택한다.
이를 수식으로 표현하면 아래와 같다.

Decoder의 Sequence, output의 확률 분포, max의 대상 무수히 많이 생성되는 후보들 중 어떤 sequence를 선택하라 지 정하는 방법 중 하나가 바로 Beam Search이다.
Greedy Search(Decoding)
Seq2Seq에서 가장 대표적으로 사용하는 방법으로, 해당 t시점에서 가장 확률이 높은, 가능성이 높은 단어를 고르는 방법이다.
Complexity 관점이나 구현 관점에서는 매우 좋지만 해당 해가 최적이라는 보장이 없다. 즉, 전역적으로 최적이라는 보장이 없다는 것이고, 이는 전체 문장을 보았을 때 옳지 않은 문장일 수 있다라는 점이다.

https://www.geeksforgeeks.org/search-algorithms-in-ai/ Beem Search
Beam search는 위의 Greedy 알고리즘의 한계를 극복하고자, 여러 후보를 만들어 비교하는 방법을 선택하였다.
예를 들어 K=3이라고 하자.

Beam search 그러면 우선 start를 바탕으로 3 단어를 선택한다(K개).
이후 3개의 후보를 더 만든 뒤, 이 중 가장 확률이 높은 3개를 고른다. 즉, K의 제곱개의 후보 중 누적확률 순으로 상위 K개를 뽑는다.
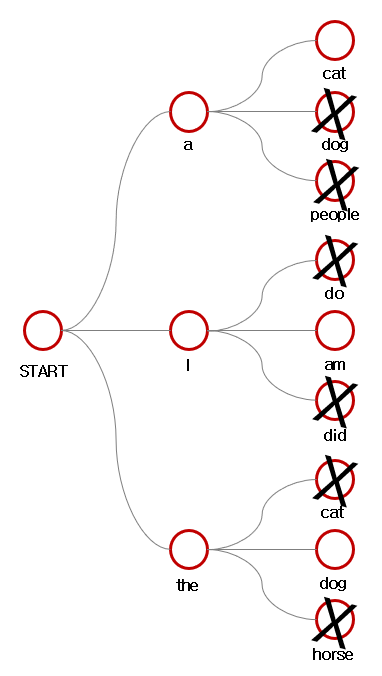
K개 선정 이후 이를 반복하다가 <eos>를 만난 빔이 K개가 될 때까지 이를 반복한다.
마지막으로 총 K개의 후보 중 가장 높은 확률을 지니는 빔을 최종적으로 선택한다.
Length Penalty
이때, 핵심적인 내용이 바로 Length penalty이다. 확률은 0~1사이의 값임으로 이를 누적하여 곱할 수록 자연스럽게 크기가 작아진다. 즉, 짧은 문장이 더 선호되게 되는 것이다.
이를 해결하기 위하여 Length Penalty는 길이가 길어짐에 따라 값을 보정해주는데 이때 알파는 보통 1.2정도의 값을, lp에 적힌 5는 minmum length로 Length Penalty를 적용할 최소한의 단위를 말한다.

'ML&DL 이야기 > ML' 카테고리의 다른 글
[NLP processing] 자연어 데이터를 전처리해보자! (1) 2024.02.23 [NLP] BLEU Score(Bilingual Language Evaluation Understudy) (0) 2024.02.16 [NLP] RNN, LSTM과 NLP 개론 (1) 2024.02.13 [ML] Convolution 합성곱의 정의와 FFT 고속푸리에 변환에 관하여 (1) 2023.10.08 [ML] Regression과 Logit(승수)와 Sigmoid함수 그리고 Softmax함수 (0) 2023.10.02