-
[Transformer] Attention is All you need(NIPS 2017)Paper Review(논문이야기) 2024. 2. 19. 14:41
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
https://github.com/huggingface/transformers?tab=readme-ov-file
공식 transfomer 구현 github 레포
GitHub - huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
github.com
기존의 Attention(Neural Machine Translation by Jointly Learning to Align and Translate)에서 알 수 있듯이 RNN의 Long term dependency 문제에 따라 Attention 메커니즘이 제안되었다.
하지만, RNN 기반 Encoder, Decoder를 이용하여 여전히 순차적으로 데이터를 처리해야한다는 제약점이 존재하였다. 이는 순차적으로 Sequence data를 받아 처리하기에, 그 길이에 따라 학습시간이 증가(computation cost & memory problem)한다 말이다.
이를 위해 RNN을 제거하고 Attention만을 이용하여 주요 정보를 찾아, 병렬처리를 할 수 없을까? 하는 생각에서 제안된것이 Attention is All you need이다.


출처: 허민석님의 Transfomer 영상 중 / 두 그림의 차이를 보자! Model Architecture
아래가 Transfomer의 구조이다. 각 부분을 하나씩 살펴보자.
Transfomer의 경우 Encoder와 Decoder layer 모두 6개로 구성되어있다.
즉, 단일 layer가 아니다.

Attention is all you need 논문 출처 Remove RNN? & Positional Encoding
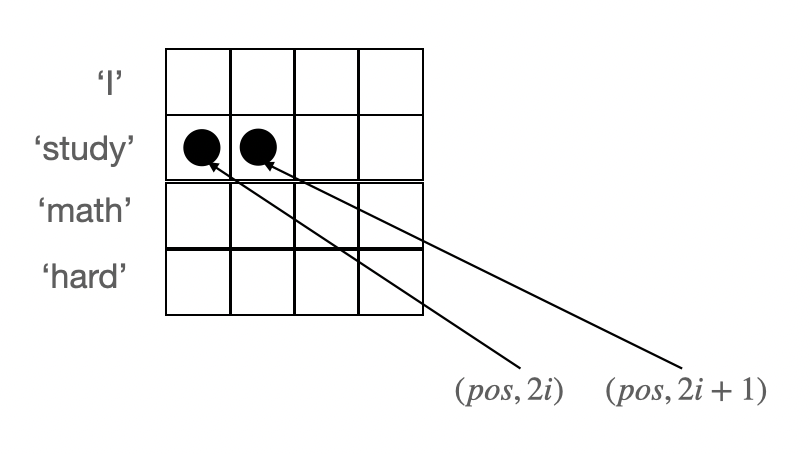
RNN 계열의 모델이 자연어처리에 사용되던 가장 큰 이유 중 하나는 바로, 단어의 입력 순서라는 정보를 담을 수 있었기 때문이다. 하지만, Transfomer 모델에서는 RNN을 모델을 제거하고, 각 단어를 병렬적으로 입력하기에 별도로 입력 순서 정보를 담아줄 방법이 필요했다. 그것이 바로 Positional Encoding이다.

출처: 주재걸 교수님 Transfomer 강의 Positional Encdoding은 문자 그대로, 각 단어의 position 정보를 담아 주는 것이다.
다양한 방법을 선택할 수 있지만, 본 논문에서는 sin과 cosine 함수를 사용하였다(어떤 가변적인 길이여도 sin, cos이 대응 가능하고, 값의 크기가 1~-1로 범위가 고정된다). 추가적으로 주기함수기 때문에 값이 반복되지만, 그만큼 긴 주기를 가지는 경우 단어간 attention 자체가 떨어짐으로 큰 문제가 없을 것이다(positoal encdoing 함수 자체가 홀,짝수인 경우 각각 다른 함수를사용함으로써 긴 주기를 가지게 되었다)
수식을 살펴보면, pos는 position(함수의 x로 들어감), i는 dimension(전체 sequence의 길이, 모델의 임베딩 차원)이다. 논문에서 이 함수를 사용한 이유로 고정된 offset k에 대하여 $PE_(pos+k)$가 $PE_(pos)$의 선형함수로 표현 가능하기에, 모델이 쉽게 상대적인 위치를 참조할 수 있을 것이라 생각했기 때문이다.
Self Attention
Self Attention의 input으로 Query, Key, Value, 총 3개의 matrix(단어 기준으로는 vector)가 들어온다.
이때, Query는 정보를 찾고자 하는 단어, Key는 Query가 찾으려는 source의 주체(물어볼 곳), Value는 각 데이터의 값(각 단어의 정보)을 의미한다(앞에 Q,K는 문맥상 각 단어가 참조할 Attention 정보를 V는 해당단어 자체의 의미를 담고 있다). 이 Q, K, V는 동일한 단어집합의 선형변환된 형태(학습 가능한 가중치 matrix를 가각 곱한 형태)임으로, Self Attention == 자기 스스로에게 Attention 쓰기라고 불리는 것이다. 수식의 결과로 나오는 것은 특정 단어에 대응하는 encoding vector의 값으로 이는 해당 단어가 각 문장에서 차지하는 Attention 정도를 의미한다.

출처- Attention is all you need / Attention 수식 수식을 살펴보면 위와 같다, 수식을 하나씩 살펴보며 이해해보자.
만일 Encoder에 "AI is awesome"이라는 문장이 들어왔다고 해보자( Query q는 보통 matrix로 묶어서 사용하지만, 이해를 돕기 위해 vector 하나에 관해서만 뺐다. )
이때, Awesome이 문장에서 얼마나 영향이 있는지 보기 위해, 전체 문장에 해당하는 matrix인 Key와 행렬곱을 하면(물론 둘 중하나는 전치를 한 후 곱한다), Attention Score가 적힌 matrix가 나올 것이다.
그림을 보면 120, 10, 240은 각각 Awesome이 AI, is, awesome에 얼마나 연관되어있는지를 알려주는 vector의 각 요소이다.
우리는 이 값을 그러면 Softmax로 묶어 확률에 관한 값으로 변환한다.

이후 이 Attention Vector(혹은 relation Vector)를 value marix와 다시 내적함으로서 우리는 value의 가중평균 vector를 최종적으로 얻을 수 있다(이 때 가중은 Attention이 사용된다). 이는 즉, 각 문장에서 특정 단어가 얼마나 영향을 끼치는지를 나타내는 값일 것이다.
square root of d
추가적으로 수식을 보면 softmax를 취하기 전에 d, 즉, dimention의 수로 scaling을 하는 것을 확인할 수 있다.
이는, Key vector의 차원이 증가시(문장의 sequence가 길 때) Score가 증가하는 것을 방지하는 용도이다.
차원이 커지면 커질 수록, 더하는 원소의 수가 많아지기에, 값들간의 분산이 커지게 된다.
이렇게 되면, Softmax의 결과로 나오는 확률 값 중 하나가 peaked한 값을 가지는 문제가 생긴다. 이는 gradient가 작아지는 문제를 일으키기에 Scaling이 필요하다.

Multi head Attention
추가적으로 위에서 적용한 Attention 기법을 병렬적으로, 여러 Attention을 이용하는 기법을 Multi head Attention이라고 한다. 이는 모호한 문맥상의 정보를 다른 관점에서 수집하는데 도움을 준다.

Multi Head Attention 예를 들어, I eat dinner at home at 7pm. 이라는 문장이 있다고 해보자.
우리는 I를 eat이라는 행동에 집중해서 해석할 수도 있고, 혹은 집이라는 장소에 관해서나, 시간에 집중해서 해석할 수도 있다.
만일, 단일 Attention을 이용한다면, 여러 관점이 아닌 하나의 관점에서 Encdoing이 이루어지기에 여러 Attention을 이용해 이를 극복하려는 것이다.
즉, Sequence encoding을 어떤 기준으로 할지 정하지 않고, mutli로 여러 관점에서 보자는 것이다.
이후 각 병렬 처리된 결과는 Concat한 후 W라는 가중치 vector를 통해 lienar transform되어 원하는 차원으로 변환하여 이용된다.

Add&Norm
논문에서는 수식상으로 LayerNorm(x + sublayer(x))로 표현되어있는 부분이다. 이때 sublayer는 self-attention layer와 feed foward layer 모두를 의미한다. 즉, 각 단계에 모두 Add&Norm이 적용되었다. 이때 Add는 Skip connection을 Norm은 layer normalzaion을 의미한다.
Residual Learning in Attention(Add)

입력차원과 출력의 차원을 동일하게 맞추었기에 Residual Learning, 즉, skip connection을 적용하는 것이 가능하다. 역전파에 의해 position에 해당하는 정보가 손실될 수도 있는데, Resnet을 통해 Posistion 정보가 희석되지 않고 잘 전달되게끔 해준다.
Layer Nomarlization
Encdoer와 Decoder 모두에 위의 Residual connection을 사용한 이후, output에 대해 layer normalization 또한 적용해주었다. Layer Normalzation은 각 단어 vector(feature별로)들에 대해 정규화 함으로써 gradient vanishing 문제에 대응하기 위함이다.
Batch Norm은 입력의 배치별 평균과 분산을 사용하기에 배치 크기나 특성에 민감하지만, layer normalizaton은 단일 sample당에 이루어짐으로 이에 덜 민감하다.
Layer norm은 아래 그림과 같이 정규화와 Affine transformation 2단계로 구성되며, Affine transformation은 정규화된 입력에 대해 학습가능한 Scale과(y=ax+b 중 a) shift(b에 해당) 파라미터를 적용하는 것을 의미한다.
스케일(scale)은 입력의 각 특성을 조절하여 네트워크의 표현 능력(representational capacity)을 증가시키고, 시프트(shift)는 입력의 평균을 조절하여 네트워크가 데이터에 적절하게 적응하도록 한다. 이를 통해 데이터 분포를 정규화하면서도 모델을 학습가능한 매개변수를 사용해 표현력 또한 향상시키게 된다.

Decoder
Decoeder에도 동일하게 Attention이 적용되나, Encdoer와 다르게 Masked self attention이 사용된다. 이는 정답을 순차적으로 생성해야하는 Decoder의 특성상, 필요한 것이다.
Masked self-attention
Masked, 즉, 가린다는 의미대로, Decoder의 경우 현재 상태만을 이용해 답변을 생성해야하기에 필요한 작업이다.
예를 들면 나는 집에 간다라는 답변을 생성하는 Decoder라고 하자.
이때, Encdoer와 다르게
나는 생성할때에는 집에라는 뒤에 오는 단어에 관한 정보는 알 수 없어야한다(추론을 미래를 앞질러서 할 수는 없기에)
그럼으로 미래 정보에 관한 단어들은 값을 -무한으로 만들어, softmax 적용 시 0으로 만드는 것이다.
어렵게 표현하면, " sequence model의 auto-regressive property를 보존해야하기 때문에 masking vector를 사용하여 해당 position 이전의 벡터들만을 참조하게끔 한다(이후에 나올 단어들을 참조하여 예측하는 것은 일종의 치팅)"라고 할 수 있다.

Label smoothing
논문에서 label smoothing 값으로 0.1을 사용했는데,
이는 정답 lable의 경우 일반적으로 one hot encoding 시 1로, 정답이 아닌 경우 0으로 하지만 Lable smoothing으로 0에 가까운 1에 가까운 값으로 변형하여 모델이 정답에 강한 확신을 가지지 못하게 한다.
즉,
- 정답 클래스에 대한 확률을 1 - epsilon으로 설정
- 다른 클래스들에 대한 확률을 epsilon/(클래스 개수 - 1)으로 설정
한다.
이는 모델이 학습데이터에 치중하지 않게 해준다, 즉 일반화와 overfitting을 해결하는데 도움을 준다.
학습데이터가 매우 깔끔하지 않은 경우, label이 noisy한 경우, 같은 입력값에 다른 출력값이 많은 경우에 도움이 되는 기법이다. noisy한 경우에도 one hot encoding을 적용한다면, 학습마다 가중치가 매우 크게 변해 학습이 원활히 이루어지지 않는다.
기계번역에서 Thank you를 감사합니다로 번역 가능하지만, 문맥상 고마워로 해석이 가능한 것처럼, 정답이 1-1대응되지 않기에 이를 적용한다.
3 types of Attention in Model
즉, 모델에서 Attention은 그 input과 output, 즉 목적에 따라 3종류로 구분할 수 있을 것이다.
- "self-attention in encoder": encoder에서 사용되는 self-attention으로 queries, keys, values 모두 encoder로부터 가져온다. 이를 통해 문장에서 특정 단어가 문장의 모든 단어들과 어떤 관계를 가지는지(correlation)를 학습한다.
- "(masked)self-attention in decoder": encoder의 self-attention와 같지만, masking을 통해 sequence model의 auto-regressive property를 보존한다. 즉, 해당 position 이후의 벡터들을 참조하지 못하게 한다.
- "encoder-decoder attention": decoder에서 self-attention 다음으로 사용되는 layer로, queries는 이전 decoder layer에서 가져오고, keys와 values는 encoder의 output에서 가져온다. 이는 Decoder에서 단어가 Encoder의 어떤 부분을 참조해야할지를 학습하는 부분이다.
Result
Transfomer의 성능은 크게 3가지 관점에서 해석 가능하다.
1. Complexity
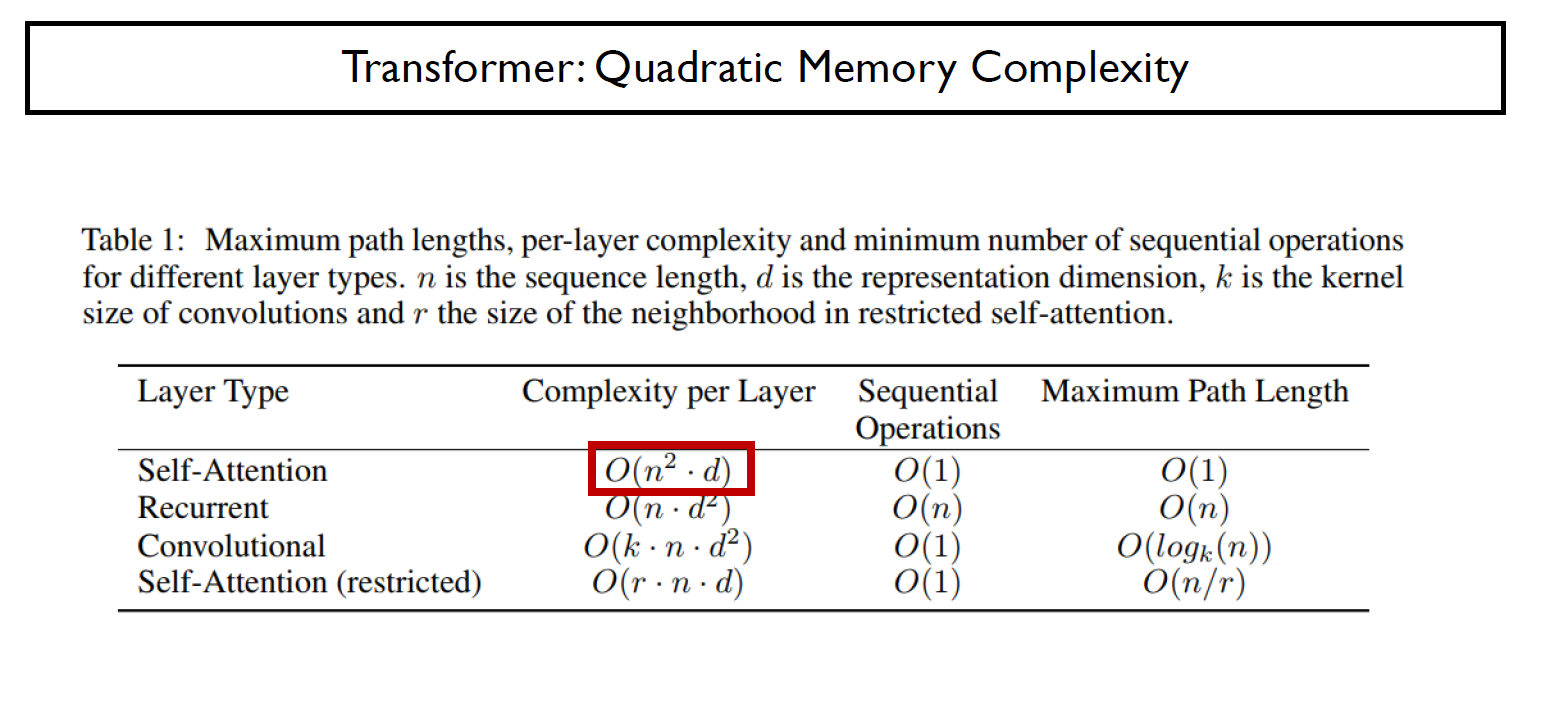
Transfmoer Complexity Table1에서 보면, n은 sequence length이고 d는 representaton dimension을 의미한다. 이때 Recurrent 모델과 비교하면 일반적으로 n이 d보다 작음으로 time complexity가 더 작다고 할 수 있다.
Restricted Self-Attenton은 오직 r 범위의 단어들만 고려하는 모델이다(기존의 n, 모델 전체와 비교하던것과 다름, n-gram 생각하기)
하지만 Memory 관점에서 보면 우리는 n의 제곱 크기의 행렬 계산을 수행해야하기에, sequence의 길이에 따라 메모리 요구량이 기하 급수적으로 필요함을 알 수 있다.
2. Machine Translation

English-to-German translation task에 대해서 다른 모델들과 성능을 비교한 실험 결과를 보면, BLEU score를 보면, Transfomer가 다른 모델에 비해 높은 성능과 동시에 training cost도 낮은것을 볼 수 있다.
(* Training cost에 작성된 FLOPs는 FLoating point Operation Per Second 의 약자인 단위 시간 (1s)에 얼마나 많은 floating point 연산을 하는지에 관한 지표가 아니다. 부동소수점 계산 시간이 컴퓨터의 성능을 나타내는데 주로 사용되나, 딥러닝에서의 FLOPS 는 단위 시간이 아닌 절대적인 연산량 (곱하기, 더하기 등)의 횟수를 지칭합니다. 따라서 약자도 FLoating point OperationS이다. 이는, 각 operation 연산을 1로 보고( 더하기, 빼기, 곱하기, 나누기, exponential, log, square root 등 ) 보고 그 횟수를 계산한다)
3. Model Version

모델의 여러 변형을 가한 결과, B)key size 를 너무 줄이면 quality가 안좋아지고 (C) 큰 모델이 더 성능이 좋으며, (D) drop-out이 오버피팅을 피하는데 도움이 된다는 것을 볼 수 있다.
4. English Constituency Parsing

Transformer가 다른 task에서도 잘 동작하는지를 보기 위해서 English Constituency Parsing task에 적용한 결과이다. Constituency Parsing은 특정 단어가 문법적으로 어디에(noun, verb 등) 속하는지 분류하는 task이다.
결과를 보면 transformer를 해당 task에 맞게 tuning하지 않았음에도 불구하고 좋은 성능을 보여준다.
Conclusion & Further
Transfomer 모델은 기존의 RNN을 성공적으로 제거하면서 병렬처리와 함깨 Long term dependecy를 해결해 큰 주목을 받았고, 이후 대표적인 Architecture로 자리잡았다. 하지만 여전히 Auto regressive model이라는 한계는 존재한다.
그럼에도 불구하고 이후 Transfomer는 Tansformer의 layer 수를 늘리되, model의 cell은 비슷하게하며 self supervised 를 적용해서 좋은 성능을 보여주는 방법들이 제시되었고, 또한 NLP 분야에서만 머무는 것이 아니라, 다양한 분야에 적용되었다. 특히 Vision Transformer의 등장으로 Computer vision에서도 적용이 가능해졌다(ViT).
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Reference
LG Aimers 주재걸 교수님: Transformer 강의
허민석님의 트랜스포머 (어텐션 이즈 올 유 니드)
'Paper Review(논문이야기)' 카테고리의 다른 글