-
[NLP&Finance] Analyzing Stock Market Movements Using Twitter Sentiment AnalysisPaper Review(논문이야기) 2024. 3. 16. 12:39

https://dl.acm.org/doi/pdf/10.5555/2456719.2456923
오랜만에 arvix에 없는 논문 리뷰다. 큰 흐름만 보고 상세한 내용들은 향후에 필요하면 추가할 예정이다. 순서 부분에서는 편의를 위해 변경이 있었다.
BackGround
Regression model & R-square Score
linear regression is a statistical model which estimates the linear relationship between a scalar response and one or more explanatory variables(출처 wiki)
회귀분석의 경우 특정 변수와 설명하고자 하는 변수(종속 변수나 y)의 관계를 알아내기 위한 식으로 보통 잔차를 최소화하는 파라미터를 찾는다.
이때 회귀식이 통계적으로 유의한지 변수가 유의미하게 영향을 끼치는지에 대해 다양한 지표를 통해 확인 가능한데,
F-statistics를 통해 회귀식의 통계적 유의미성을, P-value를 통해 각 변수가 종속변수에 얼마나 유의미한지를 호가인 가능하다.
그리고 가장 잘 알려진 R-square Score는 회귀식이 종속변수의 몇%를 설명할 수 있는지 알려주는 지표로 설명력을 의미한다.

이때 SSE는 관측값에서 관측값의 평균을 뺀 값, SST는 추정값(회귀식)에서 관측값의 평균을 뺀 값이고, SSR은 관측에서 추정값을 뺀, 잔차의 총합이다.
독립변수의 개수가 증가하면 R은 일반적으로 증가하기에 Adjusted R-Square을 통해 독립변수의 증가에 대응하는 Adjusted R-square도 있다. 식은 아래와 가으며 표본의 수 n과 독립변수의 수 k가 추가된 것을 확인가능하다.

사실 수식보다 그림으로 이해하는게 빠르다.
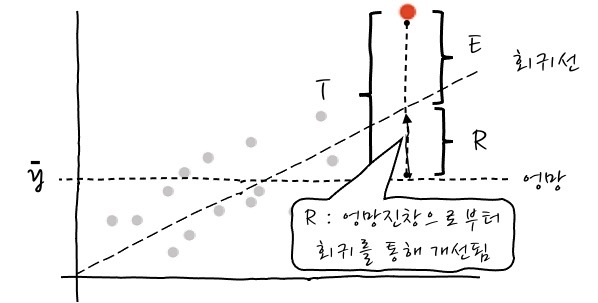
출처: https://recipesds.tistory.com/entry 즉, 우리의 R은 T(전체 차이) = R(엉망과 회귀 비교) + E(회귀와 관측비교)에서 R/T 즉, 회귀로 개선된 차이/전체 차이로 보면 된다.
자세한건 이 링크를 통해 확인하면 좋을 거 같다.
Granger’s Causality Analysis
We say that a variable X that evolves over time Granger-causes another evolving variable Y if predictions of the value of Y based on its own past values and on the past values of X are better than predictions of Y based only on Y's own past values (출처: wiki)
Granger’s Causality Analysis는 회귀 분석에서 인과관계를 통계적으로 확인하기 위한 방법이다. 즉, 한 변수의 변화가 시차를 두고 다른 변수에 영향을 미치는 경우를 뜻한다. 이때 일반적인 인과관계와 다르게 확대해석을 유의해야한다고 한다.
간단히 이해한바로는 시차를 둔 회귀분석..?으로 이해했다.
EMMS Model
EMMS model은 시계열에서 주로 쓰는 Exponetial smoothing, ARIMA, Seasonal Arima 등을 포함하고 있는 분석 set를 의미한다고 한다. 위의 대표적 모델들은 시계열 톱아보기에서 자세히 설명을 할 예정이다.
시계열 모델의 성능지표
MaxAPE: maximum Absloute Perentage Error, 절대 퍼센트 오차의 최댓값

다만 MaxAPE는 실제 값이 분모로 들어가기 때문에, 예측값에 비해 실제값이 장가지면 해당 수치가 기하급수적으로 올라가는 문제가 있다. 이로 인해 실제값의 fluctuation(변동)이 매우 크다면 전체 MAPE에 악영향을 준다.
자세한 사항은 wiki참조
Direction Score: 방향성 점수
시계열 데이터의 방향성을 얼마나 잘 예측했즈니에 관한 지표로, 금융데이터에서 주로 사용하는 지표이다.
0~1사이의 값으로 표현되면 식은 아래와 같다.

이때, correctness는 상승과 하락을 맞춘지 여부로 판단한다.
즉. 아래와 같이 정의하는 것도 가능하다.
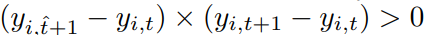
기타 용어(약어 & 경제 관련 용어 위주)
DJIA (Dow Jones Industrial Average) 다우존스 산업평균
GPOMS: "Google Profile of Mood States"의 약어로, Bollen 등이 개발한 지수. 이 지수는 인터넷 사용자의 감정 상태를 파악하기 위해 Google Trends 데이터를 활용하여 이를 통해 대중의 감정과 종가 등의 금융 지표 간의 상관 관계를 탐색하고 분석하는 데 사용한다.
Bullishness: 긍정적인 감정이나 태도, 주식의 상승 트랜드를 예측하기 위해 사용(bull market & Bear Market)
Introduction
인터넷이 나오기 전에는 주식의 가격, direction 등에 관한 정보가 사람들 사이에서 전파되는데 오랜 시간이 걸렸고 해당 정보들이 시장에 반영되는데까지는 상대적으로 오랜 시간이 걸렸다.
하지만 인터넷과 web technology의 발달로 해당 정보는 빠르게 퍼지게 되었다.
즉, 단기적인 감정(사람들 간의 분위기)가 금융시장의 단기적인 방향에 많은 영향을 끼치게 되었다.
Short term sentiments play a very important role in short term performance of financial market instruments such as indexes
이번 연구에서는 간단한 message board approach를 적용하여(특정 주제에 대해 의견을 공유하기 위한 온라인 커뮤니티)를 적용하여, 관련 커뮤니티에서 증권시장 혹은 idex에 관한 용어(return, volume, volatility)에 관한 positive and negative vector를 이용했다.
해당연구를 통해 트위터의 지수/주식에 관한 sentiment dynamic을 정량적으로 측정하여 Standard model의 성능을 높이는 것에 있다.
기존 비슷한 연구로는 E. Gilbert and K. Karahalios, “Widespread worry and the stock market,” , T. O. Sprenger and I. M. Welpe, “Tweets and Trades: The Information Content of Stock Microblogs,”의 연구는 블로거들의 글을 분석하여(Fear, anxiety 등의 관점에서) Monte Carlo 시뮬레이션을 활용하여 S&P 500 지수의 시장 변동에 사용하였다.
또한 Bollen 등은 다우존스의 종가 변동을 "Google Profile of Mood States"(구글 trends기반 감정분석) 통해 해석하려고 했고, Sprengers 등은 S&P 100 기업의 개별 주식을 분석하고 해당 회사에 대한 토론에 관한 tweet 데이터와의 연관으 해석하려고 했다.
Web Mining & Data Preporcess
A. Tweets Collection
우선 tweeter의 정보는 Twitter API(easily accessible at- https://dev.twitter.com/docs)를 통해 수집했다고 한다. 250M(2억 5000만개)의 twitt이 매일 작성된다고 하고. 이번 연구에서는 2010년 1월 2일부터 2011년 7월 29일까지, 14개월간 데이터를 수집, 4.025,595(400만) tweet을 100만(1/08M) 유저에게서 추출했다고 한다.
해당 tweet들은 영어로 작성되었고, (a) tweet identifier, (b) date/time of submission(in GMT), (c) language and (d) text의 정보를 포함하며, 정확한 방법을 밝히지는 않았지만, DJIA, NASDAQ-100 및 기타 주요 기업에 초점을 맞춰 분석했다고 밝혔다(table 1참고)
B. Sentiment Classification & Balance?
sentiment classfication을 위해 매일 수신된 각 트윗을 긍정, 혹은 부정으로 분류, 각 일자별로 긍정적인 트윗의 총 수는 $M_t^{Postive}$로 표현하고, 부정적인 트윗의 총 수는 $M_t^{Negative}$로 표현했다.
감성분석을 위해 Standford 연구진의 TwitterSentiment3 JSON API를 이용했다. 이 분류는 Naive Bayesian 바탕의 분류로 Twitter를 이용한 감성분석에서 많이 사용되는 분류기이다(160만개의 twitter set으로 훈련하였고. 82.7%의 정확도를 보이는 것으로 밝혀짐).
이를 적용한 본 실험에서 사용된 트윗데이터셋에서는 61.68%의 트윗의 긍정적이며, 38.32%가 부정적으로 나타나였고, 이는 대다수의 주식에 관련된 인터넷 게시판의 데이터와(7:1( M. Dewally, “Internet investment advice: Investing with a rock of salt,” Financial Analysts Journal, vol. 59, no. 4, pp. 65–77, 2003.), 5:1( M. Z. Frank and W. Antweiler, “Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards,” SSRN eLibrary, 2001)) 달리 균형적임을 보여준다
개인의견: 사실 이런 결과해석이 조금 의문이 드는게(balanced하다), 시간 시점이 너무 다른 연구 결과라 동일 시점으로 데이터를 모으고 보여줬으면 더 믿을만했을것 같다
C. Tweet Feature Extraction
본 연구에서 연구한 내용 중 하나는 정보의 확산에 따른 엔트로피가(twitt에서 특정 주식에 관한 정보) tech 주식의 관한 결정에(왜 tech에 한정했는지는 밝히지 않음) 어떤 영향을 미치는지 이다.
이를 위해 일별로 tweet feature을 추출하고, 일주, 이주, 삼주, 한달, 5주, 6주 등에 걸쳐 매개변수를 계산하기 위해 특정기간 동안의 트위터 피드의 평균을 취했다. Figure 1을 보면 알 수 있 듯, 트위터에서 추출한 주식 관련 정보는 아래와 같다.

Figure 1. 흐름도 "Bullishness": 주식 시장에서 긍정적인 감정이나 낙관적인 태도를 나타냅니다. 주식이 상승할 것으로 예상되거나 상승 트렌드에 있는 경우를 설명할 때 사용됩니다. "bullishness"를 수치화하기 위해 사용된 방법 중 하나는 긍정적인 트윗의 수와 부정적인 트윗의 수의 비율을 계산하여 지수로 표현하는 것입니다. 이것이 바로 Antweiler 등이 정의한 "Bt" 공식에서 사용된 개념(Bull Bear market의 개념을 수치화한 개념이라고 생각하자)
메시지(Message): 주식 시장에서 특정 주식에 대한 정보나 소식을 의미합니다. 이 정보는 다양한 소스에서 나올 수 있으며, 트위터나 뉴스 기사 등의 소셜 미디어 또는 언론에서도 발생할 수 있습니다.
거래량(Volume): 거래량은 특정 주식이나 시장에서 특정 시간 동안 거래된 주식의 수를 나타냅니다. 거래량이 높을수록 시장의 활발성이나 관심도가 높다고 볼 수 있습니다.
동의(Agreement): 주식 시장에서 동의는 투자자들 간의 의견이나 전망이 얼마나 일치하는지를 나타냅니다. 일반적으로 동의가 높을수록 투자자들 간의 공통된 의견이 있음을 의미하며, 이는 시장에서 일종의 합의를 의미할 수 있습니다.
선행연구에 대한 내용정리( Is All That Talk Just Noise? The InformationContent of Internet Stock Message Boards, Antweilier et al)
이때 $B_t$는 선행연구(Antweilier et al.)에 따라 정의된 지표로 이전 논문에서는 아래와 같이 유도된다.

출처: Is all that talk just noise? Antwilier et al. 이때 M은 각 상태에 따른 message x의 가중합으로 정의된다. type은 Buy와 Sell Hold 3가지로 정의되며, ratio of bullish는 Buy/Sell의 비로 결정된다.
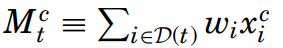
각 식을 보다 더 잘 이해하기 위해 특정 숫자를 대입해보자. 예시를 들어 보면 M buy를 600, M sell을 400이라고 하자.
(4)식의 경우, 주식 메세지 게시물에서 나타내는 매수와 매도의 감정 차를 나타낸다.
수를 대입하면, 0.2를 나타내는데, 이는 전체 message 중 의견의 차를 비율로 나타낸다. 이는 Antweilier 논문에 따르면 또한 비율임으로 +1과 -1 사이로 값이 고정된다.
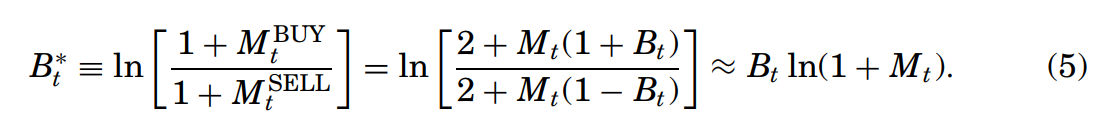
(5)식의 경우 자연로그로 묶은 것을 확인 가능한데(1을 더해주는 것으로 log의 정의에 맞게 범위 조정), 이를 통해 데이터의 스캐일링과 변화를 선형적으로 더 잘 표현할 수 있게 하였다.
동일하게 숫자를 대입해서 보면, 0.4정도가 나오고, (5)식의 경우 range를 제한하지 않는다(모든 실수 범위 값으로 나타내짐, 즉 특정 의견이 매우 큰 경우 혹은 작은 경우를 충분히 반영함)

(6)식의 경우 단순히 messgae의 차이로 정의했다.
해당 논문에서 3가지 식을 모두 성능검사한 결과 (5)가 제일 효과적인 것으로 나타났다.
추가적으로 해당 논문에서는 가중치를 동일하게(1) 적용하였다(다양한 가중치. 길이에 따라 가중하는 방식이나 동일한 작성자의 작성의 경우 가중을 줄이는 방법(역수를 취함)을 사용해보았지만 결론에 큰 영향을 끼치지 않았다고 함)
본 논문의 작성자들은 인용횟수등에 대한 가중치 적용도 고려했지만, 인용횟수는 결과에 대한 사후 결과일수 있다는 점(주식 변동이 일어나고 사후 인용이 될 수도 있음), 그리고 일부 게시판 작성자가 새 메세지를 작성하는 대신 답글을 다는 식으로 한 경우는 제대로 측정이 불가해서 이용하지 않았다고 한다.
논문에서는 이외에도 Acitivity와 Intensity를 지표로 추가사용하는데, 위와 같은 파생변수는 아니고, 다음과 같다.
Activity is measured in thousands of messages, .즉 일별 메세지의 수
Intensity is measured as the average number of words per message, 즉, message의; 단어 수
(추가적으로 이 논문에서 message의 출처는 Raging bull이라는 경제 사이트와 야후 파이넨스 게시판 데이터이다, 이는 1990년대~2000년대까지 주로 사용되던 온라인 커뮤니티이다, 현재는 레딧에 비유가능할 것이다 )
이 3변수를 return과 Volaitility와 비교한 결론은 아래와 같다(correlation, 회귀분석, GARCH Class Methods(변동성을 모델링함) 등을 이용)
(일일변동성은 15분 간격의 Movaing avergae의 로그 가격 변동의 표준편차를 1000배했다고 한다)
1. 메시지 게시물에는 유용한 정보가 포함되어 있음을 확인
2. 메시지 게시물의 긍정적인 충격(shock)가 다음날의 negative return을 예측하는 것을 확인 가능했다. 이는 통계적으로 유의하지만 거래비용(수수료등)과 비교해 경제적인 효익은 적다.
3. 메세지 게시물 간의 의견 차이와 B, 모두 거래량을 예측하는데 도움이 되는 것을 보여주었다(특히 적은 size의 거래에 관해) 하지만, 하루에 너무 큰 disagreement 발생 시 다음 날의 거래를 더 적게 예측한다(너무 불일치가 크면 오히려 거래가 줄더라 인듯)
4. 메세지는 일일빈도 및 거래일 내의 변동성 예측에 조움이 된다. 이는 market modeling과 GARCH class method에서 확인 가능했다.
결론적으로 이런 메세지들은 분명한 정보로서 가치가 있지만, 초고속거래(high-frequency stock )에는 거래비용과 거래량 때문에 큰 효용이 없을 것으로 보인다. 하지만, 거래량과 변동성을 예측하는데에는 매우 적합하다고 결론을 내릴 수 있다.
다시 본 논문으로...!
본 논문에서는 아래와 같이 각 일자별 Bullishness를 정의한다(동일한 수식이다)
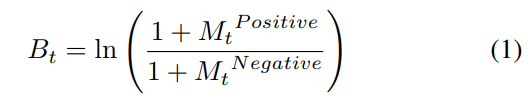
시간에 따른 message의 vol은 ln(M positive + M negative)로 정의한다(중도 의견은 따로 빼지 않은거 같다)
Agreement. 즉, 의견의 합치 정도는 아래와 같다.

이는 의견이 얼마나 수렴했는지를 보여주며, 모든 의견이 같은 경우애는 1을 나타낸다.
또한 시계열 데이터임으로 모든 정보는 d-1의 featurte정보를 사용한다(하루 전꺼를 예측에 사용한다, 당연한 얘기지만 중요하다)
Financial Data Collection
finance 데이터의 경우 Yahoo finance api를 이용 수집하였다.
수집한 데이터를 기반으로 R, return은 아래와 같이 정의했다.

Volume은 거래된 종목 수에 log를 취한 값을 사용했다.
Volatility는 Garman and Klass volatility measures에 따라 아래와 같이 구했다.

ANALYSIS AND RESULTS
Correlation Matrix
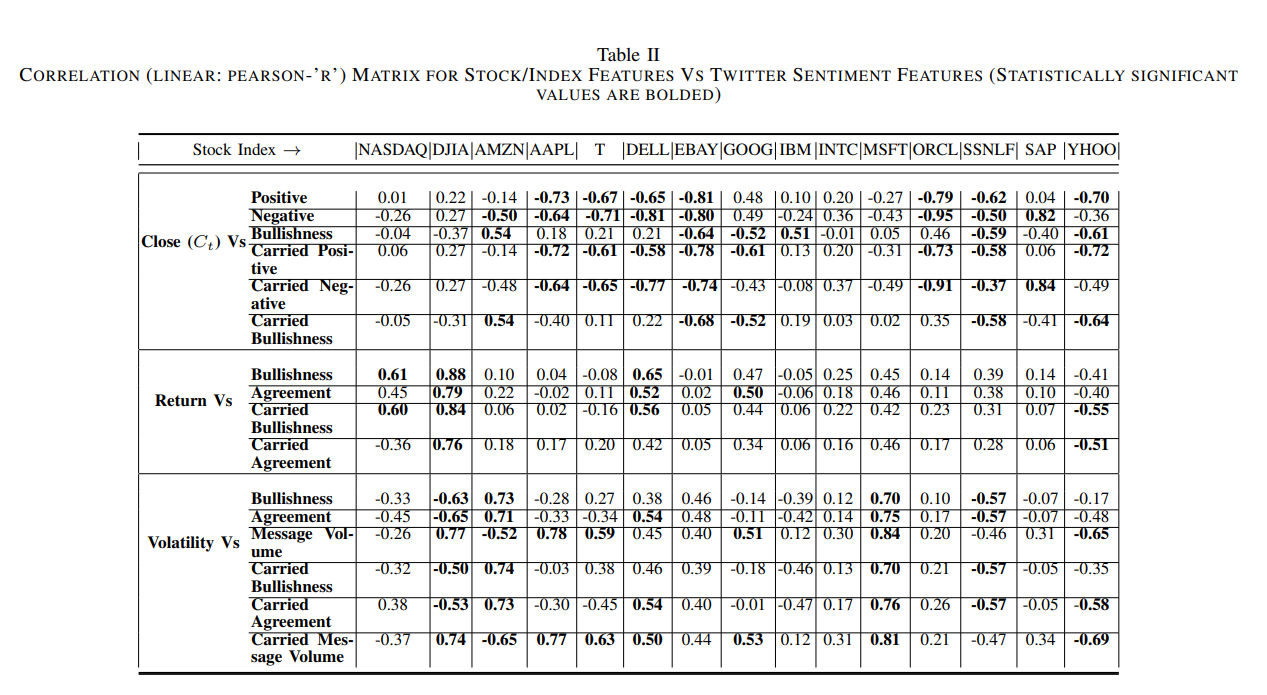
상관관계 표를 보면 알 수 있듯이, 월평균에 대한 상관성을(기간의 선정은 아래의 Prediction Accuracy using OLS Regression에서 논의됨) 확인 가능하다. 특히 DJIA 지수의 return과 0.88까지 상관성을 보여주었다.
다만 주식(지수)의 매개변수와 트위터의 message의 특성간의 관계는 그 기업에 따라 크기와 부호가 다르게 나타나기에 일관화된 표준 모델을 적용하는 것은 적절치 않으며 각 주식에 대한 개별 모델을 구축하는 것이 맞을 것이다.
큰 상관관계를 보여준 것은 DJIA 지수의 return에 관한 0.88의 상관성, Nasdaq-100의 volumne에 관한 0.6의 상관, volatlity 등이 있을 것이다.
Ebay의 경우 모두 음의 상관관계를 보여주는데, 이는 twitter의 product based marketing 을 많이 펼치고 있어서 값이 왜곡되었기 때문이라고 추측한다.
(결과 해석은 큰 의미가 없을 것 같은게, 아마 상관성이 매우 빠르게 변화할 것으로 예측된다, 이에 대한 연구가 있으면 좋을 거 같다)
Bivariate Granger Causality Analysis
Granger Causality는 앞에서 밝힌 것처럼 시계열에 사용되는 통계적인 패턴으로 X의 변화가 Y의 변화보다 특정 시점 전에 일어나는 것을 근거로 삼는다.
본 논문에서 base로 삼은 연구기법은 J. Bollen, H. Mao, and X.-J. Zeng, “Twitter mood predicts the stock market,” ] H. Mao, S. Counts, and J. Bollen, “Predicting financial markets: Comparing survey,news, twitter and search engine data,”
으로
이를 통해 시계열이 다른 시계열을 예측하는데 주요한지 검증한다고 한다.
수익률 R과 트위터의 특성변화를 비교하기 위해 다음과 같은 두 선형모델의 분산을 비교가능할 것이다.

(5)는 단순 시계열 모델, (6)은 다른 시계열 모델과의 합으로 이루어짐, 이번에는 트위터의 data 특성일 것임 즉. (5)의 경우 단순 수익률에 관한 시계열 모델(n개의 지연된 값, Rt-1, Rt-2 .. 만을 이용)이고, (6)은 Rt 및 트위터의 시계열에 해당하는 지연된 값을 모두 사용한다.
이를 통해 Table3에서 볼 수 있듯, 트위터 특성이 금융 시장의 수익률에 영향을 미치지 않는다는 귀무 가설(Ho)을 높은 신뢰 수준(높은 p값)으로 기각할 수 있음을 보여준다. 다만 이는 특정한 트윗 특성에만 적용가능하다는 것 또한 보인다(message vloume, agreement 등)
(실제로 밑의 표를 보면 알 수 있듯이, 매우 연속되고 일관되게 예측하는 것에는 실패함을 보여준다, 시계열 모델 자체를 조금 더 다듬을 필요가 보임)

표를 보면**되있는 부분이 기각된 부분, 즉 유의미한 부분 EMMS Model for Forecasting

EMMS를 이용해 시계열 모델을 만들고 예측한 결과는 위의 표와 같다.
이때 EMMS는 위에서 밝힌것처럼 지수 평활(ES), 자기회귀 통합 이동 평균(ARIMA) 및 계절적 ARIMA 모델과 같은 경쟁하는 다양한 방법을 통합한다. 이 연구에서 EMMS의 선택 기준은 결정 계수(R 제곱)였으며, 이는 적합 값(EMMS 모델에서)과 실제 관측 값 사이의 피어슨 상관 계수(r)의 제곱으로 결정했다.
예측모델에서 트윗 feature를 독립적인 예측변수로 사용했을 때(Yes)와 아닐 때로(No) 나누어 사용해으며,데이터셋은 약 60주(422일)이며, 이 중 약 75%(45주)를 예측 변수와 함께 두 모델의 학습에 사용(2010년 6월 2일 ~ 2011년 4월 14일), 그런 다음 2011년 4월 15일부터 7월 29일까지의 15주간의 테스트 기간 동안 바로 앞단을 예측하는 것으로 모델의 성능을 평가했다.
결과를 보면 예측변수로 모든 트윗의 feature(pos, neg, bullishness, message volume, agreement) 사용 시 모두 모델 성능이 향상된 것을 확인 가능하다(다만 R square의 경우 feature의 수가 늘수록 증가하기에 적합한 지표인지는 잘 모르겠음)
아래 그림에서 "fit"은 모델 적합 값, "observed"는 실제 지수 값이며 "UCL" 및 "LCL"은 예측 모델의 상한 및 하한 신뢰 한계를 보여준다(꽤나 fit 하게 맞는 것 같다)

Selecting appropriate time range
시계열 데이터를 다룰 때 time sliding window의 간격을 정하는 것, 어느 시간대의 지표를 예측할지는 매우 주요하다. 이에 따라 본 논문에서는 후자에 관한 분석결과를 보여주는데, OLS(최소 제곱 회귀(Ordinary Least Squares Regression))의 성능을 기반으로 파라미터를 추정한다(트윗을 적용한 데이터에 관해 OLS를 진행한 것으로 보임)
그림 3은 주식 지수 NASDAQ-100 및 DJIA의 수익률에 대한 OLS 회귀의 R-제곱 점수 변화를 보여준다.

그림 3을 보면 가장 높은 R을 보며준 지점인 monthly data에 관해 예측을 하는 것을 볼 수 있다.
@zin: 다만, 월별 데이터가 가장 정확하기에 적용했다...?는 너무 이상하지 않나 생각중이다.
앞서 말한거처럼 Sliding window의 간격을 정하는데 사용하는게 더 맞지 않나 싶다.CONCLUSION AND FUTURE WORK
1. 기존 연구에 비해 보다 다양한 특성과의 연관성을 확인함
2. 특히 개별회사의 주식데이터와 비교하여 특정 기업과의 높은 상관관계를 확인함
한계점(개인 생각):
왜 특정 기술 주식에 관해서만 지표를 확인했는지 아쉬움, 시계열 모델의 경우에는 나스닥과 다우존스 전체 지표에 관해 확인하였기에, 특정 기술 주식에 관한 시계열모델을 만드는 것이 맞지 않을 지 생각함
또한 최근 시계열 모델의 경우 ARIMA를 넘어 새로운 모델들이 많이 나오고 있기에 해당하는 새로운 시계열모델을 적용하면 더 좋은 결과가 나오지 않을지 생각함
'Paper Review(논문이야기)' 카테고리의 다른 글