-
[Time-series] A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers (ICLR 2023, PatchTST)Paper Review(논문이야기) 2024. 4. 25. 09:18
https://arxiv.org/abs/2211.14730
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are serve
arxiv.org
논문코드: https://github.com/yuqinie98/PatchTST
GitHub - yuqinie98/PatchTST: An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with
An offical implementation of PatchTST: "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers." (ICLR 2023) https://arxiv.org/abs/2211.14730 - yuqinie98/PatchTST
github.com
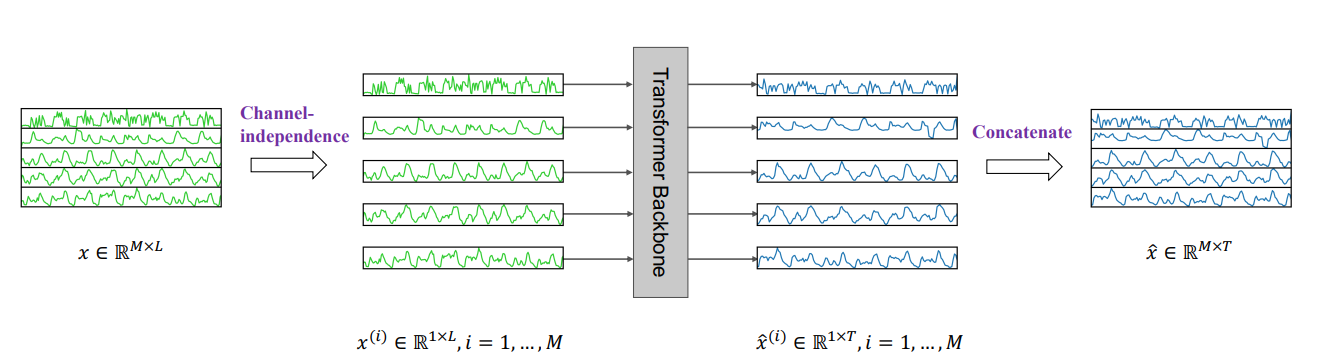
이전의 Are Transfomer Effective for Time series forcasting? 연구의 뒤를 이어, Transfomer 아키택쳐가 여전히 효과적임을 보여주는 논문. VIT에서 영감을 받아 시계열에 비슷한 방법으로 1) Patch기반으로 time series를 분해여 input token으로 입력하는 transfomer 모델을 제시. 2) Channel independece, 즉, 각 채널이 single univariate datset으로 사용되데, 같은 embedding과 transfomer 가중치를 공유하는 형태로 모델을 만들었다.
이를 통해 3가지 이점을 가지는데,
1. local sementic information이 patch를 통해 임베딩에 유지된다.
Are trans~(Zen et, al 2022) 논문에서와 같은 선형모델은 그 표혆력이 제한되어 시계열의 Representation Learning에 적합하지 않을 수 있기에 트랜스포머가 실제로 시계열 예측에 효과적임을 보여준다.
2. computation과 memory가 quadratically 줄어든다(2배 줄어든다)
기존 Transfomer는 O(N^2)의 시간복잡도와 공간복잡도를 가진다. 전처리 과정 없이 N은 input length에 해당하는 L과 같기에 병목현상이 일어날 수 있었다. Patching을 통해 N = L/S로 줄일 수 있었으며, 이때 S는 Patch의 크기를 의미한다.
3. 그럼으로 동일 GPU일때 더 긴 history(lookback window)를 볼 수 있다(동일 연산량을 지닐 때, look-back window를 늘리는 것이 가능)
일반적으로 Look back window를 늘리면 오차를 줄일 수 있지만, 이는 많은 메모리 사용량과 계산량 증가로 이어지낟. 따라서 이전 데이터에서는 Attention을 Sparse하게 적용하거나, Downsampling을 통해서 이를 해결하려고 했었다. 하지만 이번 논문에서는 Patch를 이용해 input token의 수를 늘리지 않아도(다른 논문에 비해) 긴 lookback window를 지닐 수 있게 한다. 즉 긴 과거 정보를 손실 없이 Patching을 이용해 사용가능하다.
본 논문에서는 supervised model과 self-supervised model로 나누어 모델을 설명하지만, supervised model을 이용한 time series forcasting에 초점을 맞추어 내용을 정리하였다.
Patching

patching image 출처: http://dsba.korea.ac.kr/seminar/?mod=document&uid=2670 시계열 예측은 각 time step의 correlation을 파악하는 것에 중점을 두고 있다.
하지만 single time step(or unity time step)은 단어처럼 어떤 의미를 가지고 있지 않다(시계열은 변화가 중요하지, 특정 점 자체가 정보를 지니지는 않는다). 그럼으로 관계에서 local sementatic information을 추출하는 것이 중요하다.
기존 연구들은 point-wise input token을 사용하였지만 이번 논문에서는 patch를 통해 locality를 강화하고 또한 포괄적인 정보를 담는다.
Channel Independece
다변량 시계열의 경우 다중 채널 신호(즉, 여러 변수의 정보가 담겨져있다). Transfomer에서는 input token의 정보를 sigle channel 혹은 multi channel로 표현가능한데, 이는 각 Transfomer architecture에 따라 다르다.
Channel mixing은 여러 채널의 정보를 서로 혼합하여 새로운 임베딩 벡터를 만드는 방법이다(흔히 접근하는 multivariate 접근법, infomer, fedfomer등이 이에 해당)
반면 Channel independence는 each input token이 각각의 채널의 정보만담고 있음을 의미한다. 이는 CNN (Zheng et al., 2014)과 이전에 작성한 Dlinear model등이 적힌 linear models (Zeng et al., 2022)에서 사용된 방법이다. 하지만 Transfomer-based model에는 적용되지 않았다.

Figure 1: PatchTST architecture. (a) Multivariate time series data is divided into different channels. They share the same Transformer backbone, but the forward processes are independent 결과를 간단히 요약하면 아래와 같으며, 볼 수 있듯이 Patching을 통한 시간 감소와 Channel indpendent 가 예측 성능측면에서도 효과가 있음을 보여준다(최대 22배의 속도향상)

Table 1: A case study of multivariate time series forecasting on Traffic dataset. The prediction horizon is 96. Results with different look-back window L and number of input tokens N are reported. The best result is in bold and the second best is underlined. Down-sampled means sampling every 4 step and adding the last value. All the results are from supervised training except the best result which uses self-supervised learning. Related Work와 차이점
Patch in Transformer-based Models
Transformer (Vaswani et al., 2017) 이후 다양한 분야에서 Transfomer가 적용되기 시작되었고, patching은 local semantic 정보가 중요할 때 핵심적으로 쓰이는 기술 중 하나였다.
NLP에서는 BERT (Devlin et al., 2018)에서 subword-base tokenizer로 사용되었고, CV에서는 Vision Transformer (ViT) (Dosovitskiy et al., 2021)에 적용되어, 이미지를 16*16 patch로 나누어 Transfomer에 입력하였다. 이후에도 BEiT (Bao et al., 2022, 2022 ICML for image oral), masked autoencoders (He et al., 2021)에서도 patch를 input으로 사용하였다.
Speech, Audio 분야에서도 Baevski et al., 2020; Hsu et al., 2021 등과 같이 비슷하게 sub-sequence level로 audio를 나누기도 하였다.
Transformer-based Long-term Time Series Forecasting
Transfomer를 LTSF task에 사용하려고 한 논문들은 많았으며, 정리하면 다음과 같다.
- LogTrans (Li et al., 2019): LogSparse을 이용하는 Convolutional sefl attention을 이용하여 local 정보를 잘 캡쳐하고 complexity를 LlogL로 줄임
- Informer (Zhou et al., 2021): ProbSparse Self attention을 제시하여 주요한 key 정보를 잘 추출(증류?)하는 방식을 제시
- Autoformer (Wu et al., 2021): 기존 시계열 방법론에서 decomposition 방법론과 함께 auto-correlation 제시
- FEDformer (Zhou et al., 2022): 푸리에 변환을 이용한 모델을 제시
- Pyraformer (Liu et al., 2022): 상호 스케일 및 개별 스케일 연결을 포함하는 피라미드형 attenton module을 제시
이처럼 기존의 모델들은 complexity를 줄이면서 동시에 성능을 늘리려고 하였다. 하지만, 이런 모델들은 point-wise attention을 이용하여 patch의 주요성을 간과하였다고 주장한다(LogTrans의 경우 키와 쿼리간의 point wise dot product는 아니지만 여전히 single time step에 관한 연산이고, Autofomer는 패치 내의 모든 정보를 포함하지 않는 인공적인 설계법이라고 함)

출처: 고려대학교 DSBA 리뷰 영상(아래 추가참고자료 링크참조) Triformer와의 차이점
Trifomer 또한 패치어텐션을 제시한다는 것에서 비슷하지만, 패치를 입력단위로 직접 취급하는 것이 아니기에 그 방법론이 다르다고 주장하고 있음, Triformer의 경우 학습가능한 가상의 timestemp를 도입함으로서 patch를 취급하고 있음

Triformer에서 제시하는 Patch Attention PatchTST Architecture

Figure1: (b) Each channel univariate series is passed through instance normalization operator and segmented into patches. These patches are used as Transformer input tokens. (c) Masked self-supervised representation learning with PatchTST where patches are randomly selected and set to zero. The model will reconstruct the masked patches. PatchTST에서는 위의 그림에서 알 수 있듯이 vanila Transfomer encoder를 core로 사용하였다.
Forward Process
Dataset에 관해 L만큼의 lagged value를 본다고 하자(참조할 과거 데이터 수)
그리고 M만큼의 종류의 variable로 구성되어있는 series라고 하였을때, 우선 input (x1, ..., xL)을 M univariate 시리즈로 나눈다.
그럼 분할된 dataset은 독립적으로 Transformer backbone에 들어간다(channel independence setting). 그러면 결과적으로 transformer backbone은 T개에 해당하는 xˆ (i) = (ˆx (i) L+1, ..., xˆ (i) L+T ) ∈ R 1×T의 결과를 output으로 낼 것이다.
Patching
Patching과정은 위에서 설명한 것과 같다. univariate time series에 관하여 patching이 이루어진다.
이때 N = number of patch, L은 전체 patch의 크기, P는 Patch의 크기, S는 Patch사이에 겹치지 않는 영역(step size or Stride)를 의미한다. 또한 패치 단위로 자르기 전에 데이터의 길이가 패치크기의 배수가 아닐 수도 있기에 S번만큼 마지 값을 반복한다.

patch를 통해 input token의 개수가 L에서 N, 대략 L/S 만큼 감소한다.
이는 memory usage와 computational cost가 S만큼 감소함을 의미한다. 이는 GPU의 메모리 제약으로 인해 기존 모델은 학습가능한 시계열 길이가 제한되었지만, 이를 효과적으로 늘리는 방법이기도 하다(Table 1 추가 참조)
Transformer Encoder
해당논문에서는 앞서 말했듯 vannila transfomer를 이용했다.
Patch는 Transfomer의 D차원의 latent space $\mathbf{W}_p \in \mathbb{R}^{D \times P}$에 linear projection한다.
그리고 Positional encoding은 learnable postional encoding을 사용하였다($\mathbf{W}_{\text {pos }} \in \mathbb{R}^{D \times N}$)
즉, patch는 transfomer Encoder에 다음의 xd 형태로 입력된다(input embedding 이후 + pos encoding이라고 이해하면 된다, 주저리 썼지만 기본적인 transfomer형태)

그러면 이후 H만큼의 multi head attention을 이용해
Key Query, Value matrices가 생성되고 아래의 Attention을 거친다.
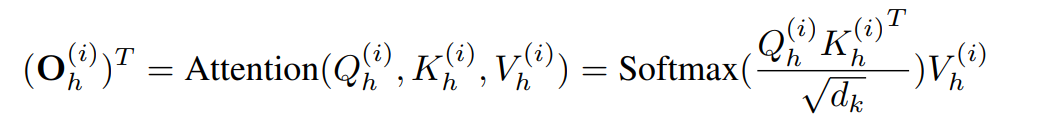
이후에도 우리가 알듯이 기본적인 Transfomer layer를 거쳐 z output을 만들게 되고 이는 D*N의 차원을 가진다(D는 dimension, N은 patch의 수). 이후 이를 flatten layer를 통해 1*T layer의 결과를 나타내게 된다.

z를 flatten하면 뒤에 T개만큼의 예측값이 나온다 Loss function
Loss function 은 MSE loss를 사용하였다.
이는 M개의(multivariate의 개수, 종류) time series의 예측의 평균을 사용한다.

Instance Normalization
instance normalization은 distribution shift로 인한 train test data의 학습문제를 해결하는 방식으로 이전에 제안되었으며(Ulyanov et al., 2016; Kim et al., 2022). 이는 단순히 각각의 time series instance를 standard normalization하는 방법이다.
이번 논문에서는 patching이전에 x의 train data를 이용하여 평균과 표준편차를 이용해 정규화 한뒤 output prediction에 해당 값을 다시 더해줘 복원시킨다.
Representation Learning Using Patch TST(masking imputation)
기존 Transfomer Self supervised learning의 문제
Self supervised learning의 경우 다양한 Task에서 unlabled data에서 좋은 성능을 보여주는 접근 방법이다.
Masked autoencoder를 이용한 self supervised learning 방법은 NLP에서는 BERT(Devlin et al., 2018 )에서 CV에서는 MAE( (He et al., 2021)가 대표적이다. 개념적으로는 간단한데 임력 시퀀스의 일부를 임의로 masking을 통해 제거하고 모델은 누락된 것을 복구 혹은 예측하도록 훈련하는 방법이다. Masking encoder 방법은 시계열 분야에서도 분류 및 회귀 task에서 좋은 성능을 보이며 사용되고 있다(Zerveas et al., 2021)
하지만 기존 방법론(시계열 분야)에서는 두가지 잠재적인 문제가 있는데 아래와 같다.

즉, 시계열에서는 단일 스탭에 관해 마스킹을 진행할 수 없다는 점과, 예측작업에 사용되는 출력 레이어 설계에 사용되는 가중치가 매우 크기에 overfitting가능성이 있다. 전자의 문제는 Zervaeas et al(2021) 논문에서는 보다 복잡한 난수화 전략을 제안하여 전자의 문제를 해결했다.
PatchTST에서는 자연스럽게 이를 극복할 수 있는데, 예측 head가 제거되고 D*P의 선형 레이어를 사용하기에 보다 단순하며, 패치를 겹치지 않는다면 패치 하나를 masking(0인 value로 만듬)하는 것은 연속된 값을 한번에 masking하며 다른 patch에서는 해당 정보를 포함하지 않게 할 수 있다.
(masking을 이용한 supervised learning은 BERT를 읽으면서 조금 더 확인해볼 예정이다)
Experiment
Datasets

Patch TST는 기존 연구에서 많이 진행되던 8개의 dataset에 관해서 그대로 진행했으며, Feature의 종류와 timestep은 아래와 같다. 보다시피 Weather, Traffic, Electiricy dataset은 특히 large dataset이며, 그 결과 ovefiiting이 잘 되지 않고, stable했다고 한다.
Experimental Settings
SOTA이자 기존의 Baseline 모델 FEDformer (Zhou et al., 2022), Autoformer (Wu et al., 2021), Informer (Zhou et al., 2021), Pyraformer (Liu et al., 2022), LogTrans (Li et al., 2019)와 Non-transfomer 모델 중에서는 DLinear 모델을 선정하였다.
이전 실험들과 동일하게 prediction length는 ILT의 경우 {24, 36, 48, 60}이고, 나머지는 { 96, 192, 336, 720 }으로 설정하였다. look back window L의 경우에는 transfomer에서는 96, DLinear에서는 336으로 설정하였다.
동시에 각 Transfomer에 관해서는 baseline에서 제시한 내용 뿐만 아니라 L ∈ {24, 48, 96, 192, 336, 720}에 관해서 실험함으로서 더 신뢰도 있는 결과를 가져왔다. 측정지표로는 MAE와 MSE를 multivariate에 관해 사용하였다.
PatchTST(main model)
PatchTST는 크게 2가지 모델을 실험했는데, PatchTST/64는 patch로 64개를 사용하였고, L-512를 사용하였다. PatchTST/42는 42개의 patch input과 L=336을 사용하였다. 두 모델 모두 Patch Lenth는 16, Stride는 8로 설정하였다.
model의 detail은 아래와 같다(A.1.4 MODEL PARAMETERS 참고)
MODEL PARAMETERS
1. 3 encoder layer를 가지고, head는 16개이다.
2. D, latent space는 128이다
3. Transfomer endcoder는 2개의 linear layer, GELU activation(F= 256으로 D를 mapping한다)과 함께 구성되어있다
(ILI, ETTh1, ETTh2의 경우에는 datasize가 작기에 H = 4, D = 16 and F = 128로 설정한다)
4. Dropout은 모든 실험에서 0.2로 설정되었다.
Implementation Details
patchTST에서는 channel을 independent하게 처리하기 때문에,Transfomer의 weight의 multiple한 복사본이 필요하다.
하지만 이런 계산은 다음과 같은 방법으로 효율적으로 구현된다.
Batch of samples x에 관하여 size는 B*M*L입니다(B = Batch size, M= # channel, L = look back window size).
이는 patching operater에 의해 다음과 같이 4D tensor, B*M*P*N로 변형된다. 이 때 P = Patch size, N= # Patch입니다.
그럼으로 x는 P*N의 차원의 data일 것입니다(이 중 x는 i번째에 있다면 각 p에서 i에 존재함)
그럼 이를 reshaping하면 (B · M) × P × N 과 같고, 이는 Batch가 transfomer에 들어가는 일반적인 term과 같다.
또한 제안된 PatchTST모델은 아래의 장점을 지닌다.
1. Transfomer backbone module은 다양한 input series에 따라 다를 수 있다(예: embedding layer와 head layer), 이 때 reshaping step이 embedding 이후에 작동가능하다.
2. 훈련 다변량 시계열의 변수 수가 testdataset의 series 수와 일치할 필요가 없다 -> Self-supervised learing에 유리함
Representation Learning(self-supervised learning)
Representation Learning을 위해 masked self-supervised learning을 실행하였고, 세부 setting으로는 아래와 같다.
Patch는 앞서 밝힌 것 처럼 non-overlapped되게 설정되었다, inputsequnce는 512, patchsize는 12로 설정하여 42개의 patch를 만들었다. Masking ratio는 40%로 설정하였다.
Pretrained으로는 100epoch을 실행하고, 이후 2개의 option으로 fine-tunning하였다.
1) Linear Probing
Linear probing에서는 10 epoch으로 model의 head를 학습시키고,
2) end-to-end fine-tuning
end-to-end fine tuning에서는 1)을 거친 이후 20 epoch으로 전체 네트워크에 관해 학습시켰다.
이 아이디어는 Kumar et al., 2022을 참고하였고, 해당 논문에서 linear problin 이후 fine-tuning을 진행하는 것이 효과적임을 입증하였기에 이를 이용했다고 한다.
Result

1- Result for Superevised Learning

결과적으로 PatchTST/64의 경우 MSE에서 21%의 reduction을, MAE에서는 16.7%의 개선을 보였고,
PatchTST/42에서는 MSE에서 20.2%의 reduction을. MAE에서 16.4%의 reduction을 보였다. Dlinear Model과도 비교해서 더 좋은 성능을 보였고, 특히 large dataset에 관해 더 좋은 결과를 보였다.
-2 Self-supervised Learning
Supervised Learning 기법들과 비교한 결과는 다음과 같다.
Table 4에서는 Fine-tuning을 한것(option 1,2를 모두 사용한것), Linear prob만 거친것, Scartch 버전의 supervised learning과 Supervised learning의 결과를 비교하였다. Fine-tuning을 간단히 하기만 해도 supervised learning의 기존 모델들보다 성능이 뛰어남을 확인 가능하다.

Supervised Learning의 결과 Transfer learning과의 성능 비교는 아래와 같다. Electiricity dataset을 이용해 Transfer learning을 위한 pre-trained 모델을 학습시켰고, 이를 다른 모델에 fine tuning하였다. Table 5는 fine-tuning한 MSE 결과가 작지만 기존 모델들보다 좋은 성능을 보이는 것을 보인다.

table 6의 경우 기존에 발표된 BTSF (Yang & Hong, 2022), TS2Vec (Yue et al., 2022), TNC (Tonekaboni et al., 2021), and TSTCC (Eldele et al., 2021) 모델들과 비교하는데, 이들은 기존 constrastive learning representation의 SOTA 모델들이다. 동일한 비교를 위해 Linear probing만을 이용하여 학습하였고, 그 결과는 위에서 알 수 있듯이 매우 큰 차이를 보임을 확인 가능하다.
ABLATION STUDY(p14이후)
ABLATION STUDY: Feature를 제거함으로서 모델의 추가한 부분이 얼마나 주요한지 해당 요소를 포함한 모델과 포함하지 않는 모델을 비교하는 실험

Table 7은 patching과 channel-independence에 관한 Albation study결과를 보여준다. Baseline모델로 FEDformer를 첨부하여 SOTA benchmark로 삼았다.
본 논문에 주요한 요인인, patching/channel indpendence 각각의 효과를 확인해보기위해 위 설험을 기획했다.
각 비교 모델 기존의 PatchTST모델에서 아래와 같이 설정하였다.
• Only channel-independence (CI): patch length와 Stride를 모두 1로 설정함으로서 patching을 없앴다.
• Only patching (P): 위의 implemetation deatail를 참고, 4D tensor로 만드는 대신에 B×(M ·P)×N으로 channel mixing만 적용함.
그 결과 각각의 요인 모두 3개의 dataset에서 좋은 성능변화를 이끌어내는 것을 확인 가능했다.
(*Weather dataset에서 FEDformer의 성능이 original(TST)의 성능보다도 좋게 나왔는데 해당 실험결과에 관해서는 확인이 필요해보임)
Patching
patch의 size는 매우 주요한 파랑미터 중 하나이다. Patch size를 lookback window size를 336으로 고정한 상태에서 4.8.16.24.32.40으로 변화시키며 실험을 진행하였고, Stride size는 각 patch size와 동일하게 진행하여 patch간 overlap이 없게 설계하였다. fig4의 결과를 보면 Patch size에 따라 MSE score가 큰 차이를 보이지는 않음을 확인 가능했다, 즉, patch length라는 hyperparmaeter에 본 논문의 모델이 강건함을 보여주는 결과라고 한다. 또한 Patch의 크기를 키울수록 computational reduction효과가 있다는 것은 매우 눈여겨볼만한 점이다(모델 구조상)

실험결과 dataset에 따라 다르지만 8, 16이 적정한 patch size로 보인다고 한다.
INSTANCE NORMALIZATION
Normalization은 많은 시계열 모델에서 예측성능을 향시키는데 사용되었던 기술(Kim et al., 2022;
Chen et al., 2022; Zeng et al., 2022)이다. Table 11은 instance normalization의 성능에 관한 Abliation study를 진행하였다. 실험에서는 PatchTST에 Instance normalization을 적용한 모델과 아닌 모델을 각각 비교하였고, 그 결과는 아래와 같다. instance norm이 적지만 성능향사엥 도움을 주는 것을 확인하였다, 하지만 이를 제외하더라고 PatchTST는 여전히 기존의 SOTA 모델들보다 뛰어난 성능을 보였으며, 이는 Patching과 channel independence가 주요한 성능개선요인임을 보여준다.

Channel-independence vs Channel mixing
직관적으로 Channel mixing 모델이 channel independence model보다 성능이 우수해야할 것이다(channel mixing의 경우 교차적인 상관관계를 더 잘 포착할 것으로 예상할 수 있고, channel independence의 경우 가중치 공유를 통해서 상관성을 보다 간접적으로 학습하기 때문이다).
하지만 실험결과는 이와 같지 않았다.
논문에서는 이를 아래의 3가지 요인으로 설명한다.
1. Adaptability
각 시계열 데이터가 Transfomer를 통과하면서 각각의 attention map을 생성한다. 이는 서로 다른 time series들이 각각의 자신의 예측을 위해 서로 다른 attention pattern을 학습함을 의미한다(아래 그림을 참고). 이는 Channel mixing에서는 모든 time seires가 동일한 attention pattern을 공유하기에 다양한 패턴을 지니는 time series를 다룰 때의 악영향을 줄 수 있다.

Fig6: Attention maps and the forecasting of a few time series from Electricity dataset run with supervised PatchTST/64. Attention map is calculated by averaging the attention matrices over all the heads and across all the layers. For each time series, we show the attention map and the prediction in orange. The blue curves are the actual data. The curves before the back lines are the actual input data. Channel-independence design allow each series to learn its own attention map for forecasting in which the pattern can be more similar for more correlated series and different otherwise. Fig6에서 볼 수 있듯이 11, 25. 81의 경우 attention map이 유사하고, 이는 다른 그림에서의 attention map과 다르다.
이를 통해 유사한 패턴을 보이는 경우 유사한 attention map이 생성됨을 확인 가능하다.
2. Channel mixing의 경우 Channel indpendent model에 비해 더 많은 Train data가 필요할 수 있다.
교차 채널의 상관관계를 학습한 다는 것은 양날의 검이 될 수 있으며,. 다양한 채널과 다양한 시간에서의 관계를 적절히 학습하기 위해서는 더 많은 데이터가 필요할 수 있을 것이다. 하지만 Channel independent 모델의 경우 시간에 따른 정보를 학습하는데에만 집중하기에 더 적은 data가 필요하다. 실제로 MSE score와 train size를 비교한 Fig7의 좍측 결과를 보면 보다 빠르게 수렴하는 모습을 볼 수 있다.
3. Overfiitng?
Channel indpendnet 모델은 ovefitting에 더 강건함을 호가인 가능하다. MSE score가 기록된 Fig7의 우측그림을 보면, Channel mixing의 경우 초기 몇번의 epoch이후에 과적합을 보이는 한편, indpendent는 그러지 않음을 볼 수 있다.

추가로 Channel independence는 다른 기존 모델에도 적용가능하기에 이를 적용한 결과는 아래와 같으며, 성능의 큰 향상을 보여준다.

Varying Look-back Window


Lookback window의 크키를 키울수록 다른 기존의 모델과는 다르게 MSE score가 개선됨을 확인 가능하다. 이는 해당 모델이 장기 시계열 정보의 학습능력이 우수함을 보여준다.
ROBUSTNESS ANALYSIS(for random hyperparameter)
아래에서 확인할 수 있듯, 다양한 parameter 조합에 관하여 실험을 실행하였다. 그 조합은 (L, D) = (3, 128), (3, 256), (4, 128), (4, 256), (5, 128), (5, 256)으로 순서대로 1~6으로 표시되었다.

Conclusion
본 논문에서는 기존 다른 모델들에서 사용되던 patching이라는 기법을 LTSF의 Task에 활용하며 Transfomer 기반 모델의 성능을 향상시켰다. 아이디어 자체가 매우 혁신적이다..!는 아니지만, Supervised Learning에만 그치지 않고 Self-supervised에도 의의를 둔 점과, 다양한 Robusteness를 검증하는 여러 실험들이 있어 아이디어의 효과를 계속 입증한 것이 눈여겨볼만한 점인것 같다(덕분에 리뷰가 길어졌...😋)
추가 참고 자료
고려대 DSBA 연구실 리뷰자료
http://dsba.korea.ac.kr/seminar/?mod=document&uid=2670
[Paper Review] A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers
[ 발표 요약 ] 1. Topic A Time Series Is Worth 64 Words: Long-Term Forecasting With Transformers 2. Overview 이번 세미나 시간에는 ICLR 2023에 accept 된 long-term time series forecasting(LTSF) 방법론 PatchTST를 공유하고자 한다.
dsba.korea.ac.kr
'Paper Review(논문이야기)' 카테고리의 다른 글