-
[DSL]TaskMet: Task-Driven Metric Learning for Model Learning(NeuIPS 2023) -1Paper Review(논문이야기) 2024. 7. 4. 11:27
https://arxiv.org/abs/2312.05250
TaskMet: Task-Driven Metric Learning for Model Learning
Deep learning models are often deployed in downstream tasks that the training procedure may not be aware of. For example, models solely trained to achieve accurate predictions may struggle to perform well on downstream tasks because seemingly small predict
arxiv.org
이전 DSL 개론(?) 리뷰에서 정리한바와 같이 Predict-optimize 문제, 즉, 2-stage문제에서 중요한 것은 Best prediction이 Best task model이 아니라는 것이다. DFL에서는 이러한 문제를 다룬 적이 있다. TaskMet은 이러한 DFL 방법론 중 하나로 최적의 예측 모델 자체를 변형하지는 않지만 모델의 학습과정을 변형하여 최적화 작업에 중요한 정보를 강조한다고 한다.
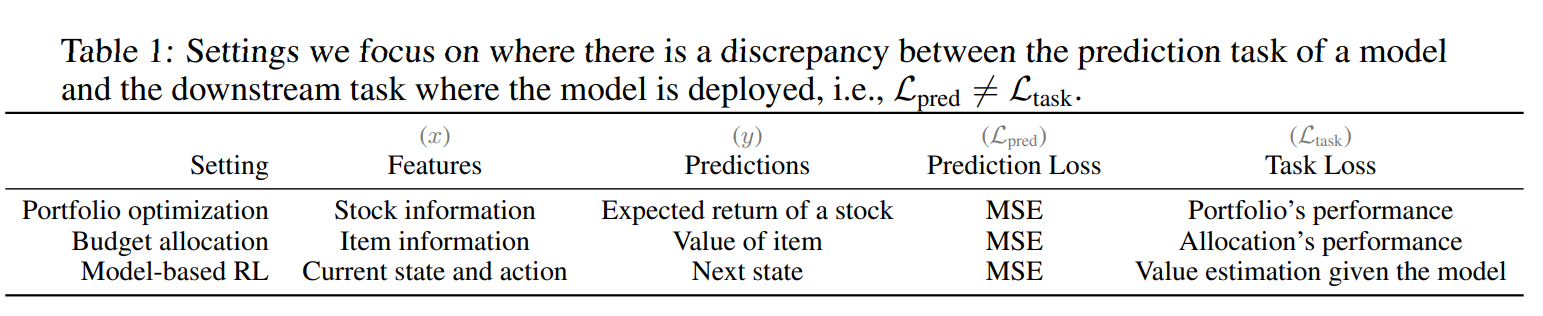
아래의 Table을 보면 Preditcion loss와 task loss가 다름을 확인 가능하다.
Introduction
Task-based model(논문에서는 기존의 DFL 방법론을 이와 같이 지칭)의 경우 task에 관련된 feature와 datasample을 모델이 end-to-end로 스스로 찾아낼 수 있게 하는 것을 목적으로 한다. 현재의 end-to-end 모델학습의 추세는 예측 손실과 함께 task loss를 사용하여 이를 훈련시키는 것이다.
이는 사용하기는 쉽지만 1) overfiiting 우려(특정 작업에 과적합) 2) prediciton loss와 task loss를 결합함에 있어서 가중치를 조절해주어야한다는 단점이 있다(실제로는 L task에서는 세타가 아니라 prediction y가 사용된다, 하지만 간접적으로 세타가 사용된다고 해도 무관해서 논문에서 아래와 같이 표현한 것 같다)

Task-based model의 loss 이에 본 논문에서는 mahalobis loss를 이용한 metirc learning을 이용한 모델 최적화 방법을 제안한다.
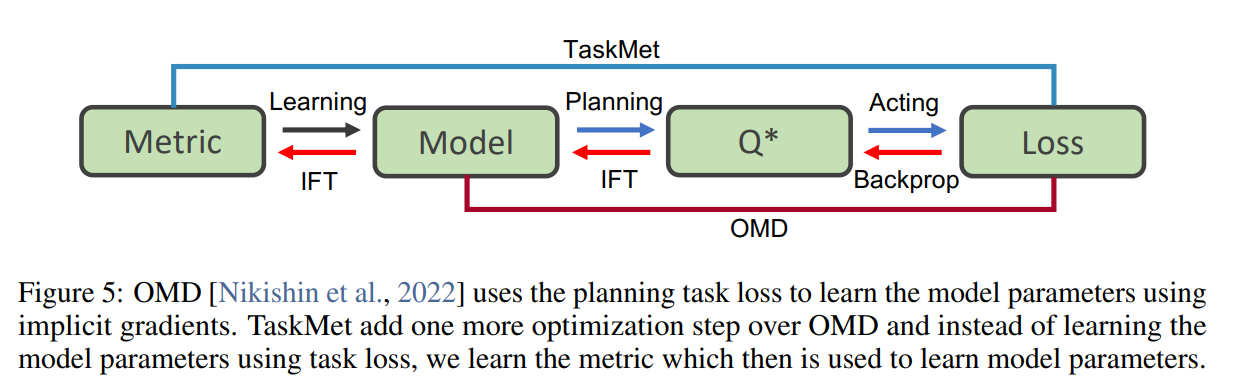
Fig5를 보면 알 수 있듯, Task loss를 이용하여 모델을 직접 훈련시키지 않고, 매개변수화 된 예측손실을 학습하는 것이 이 모델의 특징이다.
Background
Task Based Model Learning(DFL)
논문에서는 회귀 문제에 초점을 맞춘다. DFL에서 Regression은 N개의 input-output이 있을 때, 우선 x와 y를 이용해 y를 잘 예측하는 yˆ := f(x, θ)의 model을 만든다. 예측된 값 y hat은 θ에 의해 매개변수화 된다. 그럼 모델은 L pred를 얻고, L task는 구해진 y를 이용해 최적화 문제를 풀고 이에 따른 L_task를 loss로 얻는다.
즉 최종적으로 모델은 아래 수식을 최소화 하는 세타를 찾는 문제가 된다.
Task-based model의 loss 이 때 L pred는 일반적으로 MSE loss고 알파는 이를 조절하는 정규화 가중치로 사용된다.
식 1에 관한 대안으로 Smart "Predict than optimize"에서는 도함수가 정의됮 않은 경우를 위한 대체 방법을 고려하며, 혹은surrogate loss로 이를 변경하는 방법들이 제안되어왔다.
하지만 논문에서 제시하는 taskmask는 기존의 방법론들이 MSE prediction loss와 task loss를 합해 직접 모델의 업데이트에 사용하거나, taskloss를 미분하기 좋은 형태로 변형하는 등의 방법이 아닌 task loss를 통해 prediction loss를 만드는 모델을 학습하고 이를 모델 훈련에 사용하는 방법이다. 즉 task loss는 직접 모델 훈련에 사용되지 않는다.
Task Driven metric learning for Model learning
Metrics in the prediction space — Mahalanobis losses
우선 non-Euclidian 방법이 Mahalnobis loss를 metirc으로 사용하는 것이 왜 더 의미가 있는지 보인다.
Prediction model에서 기하학적 정의를 이용해 loss를 정의한다. Supervised model f가 세타를 매개변수로 지닐 때 MSE는 다음과 같이 정의된다.
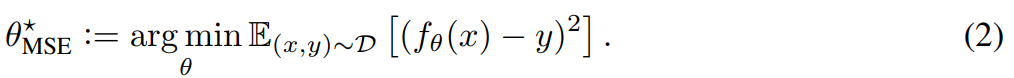
즉, x,y의 편차의 제곱의 평균을 최소화하게 정의된다.
일반적인 loss지만 이는 일부 샘플 혹은 차원을 다른 것보다 강조해야할때(모든 sample이 동일한 가치를 지니지 않을때)는 적절하지 않을 수 있다(ps. Entrophy fuzzy 개념을 사용할 수 있을까??)
본 논문의 필자들은 mahalanobis norm을 통해 metirc space를 정의한다.
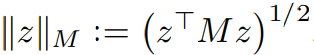
이때 M은 psd이다(일반적으로 공분산행렬이지만, 이번에는 파이로 이를 최적화하는 과정을 거치는 것 같다, Collaborate metric learning과 비슷한 과정인것 같다(https://hwa-a-nui.tistory.com/35)).
그럼 loss는 이제 아래와 같이 재정의된다.
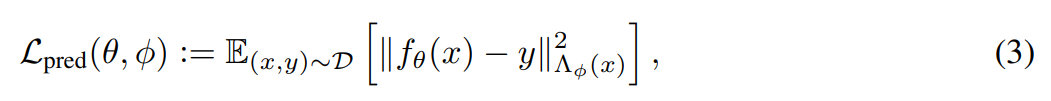
이때 Λ ϕ 는 ϕ에 의해 매개변수화된 metirc이다. 이를 통해 Φ에 따라 보다 Feature에 유연하게, 중요도를 부여할 수 있고, 예측 공간 내의 feature의 상관성을 고려하고, 샘플에 서로 다른 가중치를 부여할 수 있게 한다.
End-to-end metric learning for model learning: Changing problem to Bi-level optimization probplem

논문의 핵심 아이디어는 마할로비스 metirc으로 정의한 eq3, L_pred을 end-to-end로 학습한 후 이를 Prediction model의 학습에 사용하는 것이다. 즉, 아래의 bi-level optimization 문제로 정의된다.

bilevel optmization 이때, 각 ϕ는 metric의 parameter이고, θ는 L pred로 부터 나오는 예측값(optimize unknown parameter)이다. 또한 task loss는 문제가 풀고자하는 optimization 문제에 따라 달라진다.
Defining Gradient
optimal materic의 인자 ϕ*를 구하기 위해 gradient loss of L_task가 필요하다.
chain rule에 따라 아래와 같이 gradient loss를 정의할 수 있다.
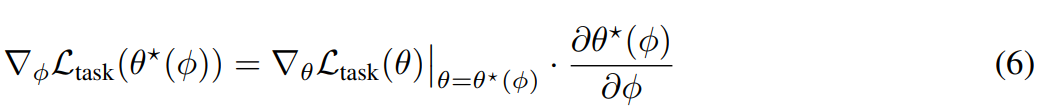
이를 계산하기 위해, 우측의 2요소를 계산해야한다.
이때, 전자는 L_task가 θ에 의한 명시적으로 나타나는 함수이기에 바로 구할 수 있지만, 후자의 경우 Multiple interation G.D(즉, 예측모델과 메트릭을 번갈아가면서 최적화해야하는 문제, metric을 L_task에 의해 업데이트하고 이에 따라 L_pred를 최소화하도록 세타를 최적화해야함, algoritim 1참고)이기에 직접 계산할 수 없으며 계산 비용이 많이 든다.

따라서 음함수의 정리를 이용하여 이를 계산한다 정리하면 아래 식이 나온다.
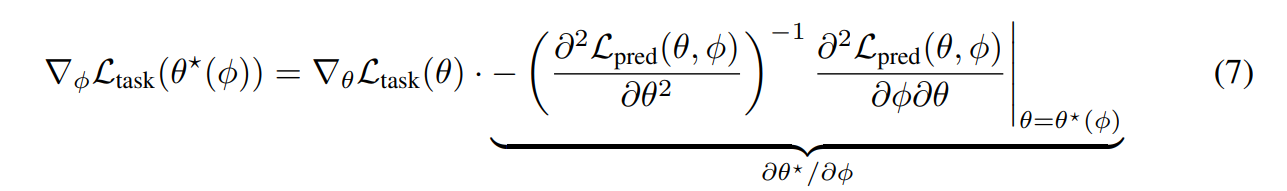
이때, 식(7)은 예측 손실의 헤이시안 부분을 계산하거나 메모리에 저장하기 어려울 수 있다, 이 때, Blondel et al. [2022] 과 Lorraine [2020]에서 언급한것과 같이 역행렬을 계산하거나 전체 Hesssian 행렬을 생성하지 않고 계산하는 conjuagete gradient를 이용한다.
Meta-learning with Implicit Gradients을 추가로 참고하면 Bi-level optimization에서 어떻게 음함수의 미분을 사용하는지 나와있다.

Meta-learning with Implicit Gradients Fig1 Counjugate Gradeint Method
수치해석때 들어본 방법, 매우 큰 시스템의 선형방정식을 iterative하게 푸는 방법
Ax=b에서 A가 매우 sparse한 경우+큰 경우에 사용가능하다. A의 역행렬을 직접구하는 것은 무리가 있기에 보다 효율적으로 문제를 바꾼다. 이는 linear eqauation을 quadiactic form으로 문제를 바꾸어 해결한다.
n개의 conjugate direction(orthogonal한 gradient)을 찾는다
부록음함수의 정리
음함수의 미분에 관한 정리, 위의 조건은 충분조건이며 양함수를 구할 수 없을 때 사용한다

위 식의 c를 정리하면

Question
여전히 Predict-Optmization 문제가 아닌가 싶은 생각이다.. DFL이 이 둘을 1 stage에 통합하기 위해 노력해던 것으로 알기에 조금 의문이 든다
'Paper Review(논문이야기)' 카테고리의 다른 글