-
[Graph] Graph Neural Networks 개론(개념정리)ML&DL 이야기/ML 2024. 3. 4. 23:10
GCN 논문 리딩을 진행하던 중, Graph에 관한 전반적인 지식이 부족하다고 느껴서, 간단히 개념 등을 정리하려고 한다.
자연어처리 관련 논문들을 읽었을 때도 느낀거지만, 전체적인 흐름을 알고 논문을 읽으면 훨씬 수훨하게 리딩이 되었기 때문에, 이번 정리를 통해 전반적인 개념과 흐름을 잡는 것을 목표로 하였다.
이번 내용정리는 "A comprehensive servey on Graph neural networks"와 이를 정리한 thejb.ai님과 glaceyes님의 블로그 whatsup의 velog을 참고, 왓챠 Medium의 글을 기반으로 정리하였고, 추가적인 출처들은 따로 기재하였다.
Graph
Graph는 wiki에 따르면 아래와 같다(이산수학에서의 graph)
In discrete mathematics, and more specifically in graph theory, a graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense "related". The objects correspond to mathematical abstractions called vertices (also called nodes or points) and each of the related pairs of vertices is called an edge (also called link or line).
즉, 보다 간결히 말하면, set of vertex and edge이다.
그래프는 흔히 딥러닝하면 생각나는 분야인 이미지, 자연어 등과 다르게 일반적으로 매우 다양한 관계를 나타내는 데이터라면 모두 폭넓게 이용가능하다(분자구조(신약개발)를 나타내거나, 교통상황 등등)
수식으로 정의하면 흔히 아래와 같이 정의한다(이산수학 참고)
- 그래프란 $G=(V, E)$로 정의된다. 즉, set of vertex and edge이다.
- 이때 V는 vertex를 의미하고, node라고도 한다(정점). E는 edge라고 하며, link라고도 한다(간선)
- $v_{i}, v_{j} \in V$일때 Edge는 $e_{i j}=\left(v_{i}, v_{j}\right) \in E$이며, 즉, $e_{i,j}$는 $v_j$와 $v_j$를 잇는 선이다.
- neighbors, or adjacent nodes는 $N(v)=u \in V \mid(v, u) \in E$로 나타내며, 문자 그대로 연결된 node를 의미한다.
- 그래프의 인접행렬(adjacency matrix)은 그래프에서 어떤 vertex끼리 연결되었는지를 표현하는 square matrix이다.
simple graph만을 가정한다면(edge가 중복되지 않는 경우), 다음과 같이 정의된다. $A: n \times n$, if $e_{ij} \in E: A_{ij}=1 else: 0$

Adjacengy matrix Why we need Graph Neural Networks(GNN)?
딥러닝의 발전은 이미지, 비디오, 언어 분야에서 많이 이루어졌다. 이 데이터들은 대다수 Euclidian space에서 나타내졌다. 하지만 Non -Euclidian space의 데이터들은 object간의 관계나 상호의존성을 정의할 수 있는 그래프로 표현가능하다.
그래프의 복잡성은 기존의 machine learning 알고리즘에 다양한 챌린지를 주었고, 최근(2019, 자료기준) 다양한 방법들이 deep learning 기법을 기반으로하여 알려지고 있다.
이 논문에서는 GNN을 크게 다음과 같이 분류한다.
- Namely recurrent graph neural networks
- Convolutional graph networks
- Graph autoencoders
- Spatial-temporal graph neural networks
Euclidian Space: 기존 Deep Learning이 잘 작용되던 분야(이미지, 추천시스템)
딥러닝에서 가장 일반적으로 많이 활용되는 기법인 CNN, RNN, AutoEncoder(Encoder-Decoder)(최근에는 Attention 기법이 대세긴 하다)을 통해 많은 머신러닝 문제들의 패러다임이 변화했고, 성공적인 성능을 보여주었다.
이런 성공은 빠른 컴퓨팅 자원의 발전(eg. GPU), 많은 양의 train data, 그리고 Euclidean data(이미지, 텍스트, 비디오)에서 latent representation을 잘 추출하는 Deep learning에 기반한 성공이었다.
CNN을 예시로 보면, 이미지를 유크리디안 공간에 regular한 grid로 표현함으로써 CNN은 shift invariance, local connectivity, compositionality라는 이미지의 특징을 모두 활용할 수 있었다.
Shift-invariance (이동 불변성): 이동 불변성은 입력 데이터의 위치 변화에 대해 모델이 일관된 예측을 할 수 있는 능력을 의미한다. 즉, 입력 이미지 내에서 특징이 이동하더라도 모델이 이러한 특징을 식별할 수 있음을 의미.
Local connectivity (지역 연결성): 지역 연결성은 CNN이 인접한 픽셀이나 특징 간의 관계를 고려하는 방식을 의미. 이미지의 지역적인 패턴이나 구조를 의미함.
Compositionality (구성성): 구성성은 더 큰 특징이 작은 특징의 조합으로 이루어진다는 아이디어를 나타냅니다. 이미지의 복잡한 패턴은 각각의 작은 특징의 조합으로 이루어지며, CNN은 이러한 구성성을 활용하여 이미지의 다양한 특징을 학습한다(CNN에서 더 깊은 layer로 갈 수록 작은 feature등을 인식하고 얕은 layer일 수록 보다 덜 추상적임을 기억하자)Non Euclidian space: Graph로 대표되는 data
비유클리드 공간은 보통 그래프로 많이 표현된다. 예시로, graph based learning system에서 추천시스템을 사용 가능하고(유클리디안 base 모델도 물론 사용가능), 화학 분야에서 화합물을 모델링 하는 분야 등이 있을 것이다.
즉, 그래프의 경우 SNS의 관계도, 분자 등 다양한 추상적인 개념을 다루기 편하며, 또한 유클리디안 space에 맵핑하는 것보다 더 다양한 문제를 다룰 수 있다.
문제는 그래프의 경우 매우 irregular하다는 것이다.
즉, Node의 size도 변화가능하며, 순서 관계(unordered set)도 없고, 이웃의 크기도 다른 등, 정해져 있기 않기에 기존의 다른 domain에서 적용되던 기법들이 효과적으로 작동하지 않는다.
특히 현재 ML에서의 가정은 바로 기본적으로 인스턴스(data)들이 독립적이라는 것이다. 하지만 그래프에서 각 노드들은 서로 독립적이지 않고(link with each other node) 여러 관계(eg. friendship, ciatation 등의 reatlion)을 가지고 있기에 해당 가정이 더 이상 성립하지 않는다.
즉, 이로 인해 기존에 활용되던 머신러닝 기법들을 적용하기에는 한계가 있었다.
최근 기존의 CNN, RNN, autoencoder를 기반으로 graph의 복잡성을 다루기 위한 연구들이 진행되었다.
그 중 예시로 CNN 기반 GCN을 간단히 보면, CNN에서 다루던 이미지는 모든 pixel들이 adjacent pixel에 연결되어있는 graph의 특수한 케이스라고 볼 수 있다. 그럼으로 2D convolution 처럼, graph convolution은 주변부(node's neighborhood) 정보의 가중평균을 취하는 식으로 convolution을 실행가능할 것이다.

출처: "A comprehensive servey on Graph neural networks" 기존의 그래프 분석방법
전통적인 그래프 분석방법은 검색 알고리즘과 경로 탐색 알고리즘들이었다.
- 검색 알고리즘 (BFS, DFS 등)
- 최단 경로 알고리즘 (Dijkstra 알고리즘, A* 알고리즘 등)
- 신장 트리 알고리즘 (Prim 알고리즘, Kruskal 알고리즘 등)
- 클러스터링 방법 (연결 성분, 클러스터링 계수 등)
하지만 이러한 알고리즘들은 다양한 그래프에 적용하기에는 입력 그래프에 관한 사전 지식을 가지고 있어야한다는 단점이 있었다. 또한 그래프의 vertex와 edge 정보를 이용한 그들간의 관계만 다루는 것이 아니라 그래프를 전체적으로 해석하는 것은 불가능하다는 한계가 있었다.
Graph Neural Networks(GNN)

출처: Representation Learning on Networks, snap.stanford.edu/proj/embeddings-www, WWW 2018 GNN이란 그래프 데이터에 적용가능한 신경망을 의미하며, 그래프를 구성하는 각 노드를 잘 표현하는 임베딩 vector를 받아서(matrix) 이를 이용해서, 특정 노드를 잘 표현할 수 있는 vector를 학습한다(이를 node embedding이라고 한다). 위의 그림의 예시라면 정점 u를 잘 표현하는 d차원의 Feature embedding된 vector를 output으로 내보내는 것이다.
이를 위해서는 우리는 Graph를 모델에 잘 입력해주어야하는데, 이때 이용되는 정보가 Adjacency matrix와 node-feature matrix(특성 matrix이다)
Input of GNN
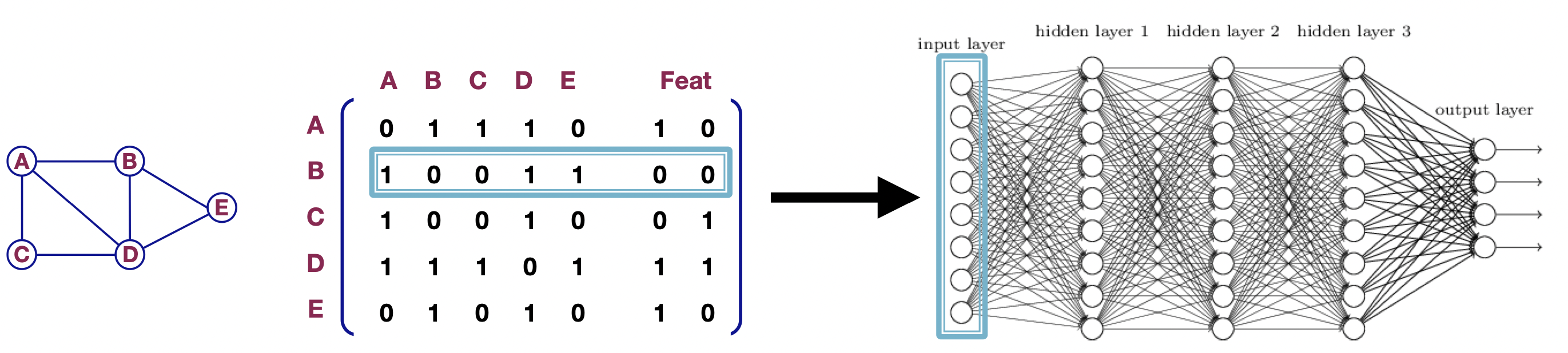
Jure Leskovec, Stanford CS224W: Machine Learning with Graphs, http://cs224w.stanford.edu Adjacency matrix와 node-feature matrix(특성 matrix이다)는 각각 아래와 같다.
- 인접 행렬 (Adjacency Matrix):
- 그래프의 인접 행렬은 노드들 간의 연결 여부를 나타내는 정방 행렬(square matrix)
- 인접 행렬은 노드들의 이웃 관계를 나타내며, 이를 통해 각 노드의 이웃 정보를 표현(1,0으로 그 연결을 표현)
- 특성 행렬 (Feature Matrix):
- 각 노드의 특성을 나타내는 행렬
- 일반적으로 각 행은 하나의 노드를 나타내고, 각 열은 노드의 특성을 나타냄. 특성에는 다양한 정보가 포함됨
GNN의 전반적인 구조 및 학습

출처: https://arxiv.org/pdf/2109.12843.pdf, Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions GNN은 그래프 구조를 통해 NN을 학습한다는 것을 제외하고근 크게 다르지 않다.
다른 점은 주어진 데이터(matrix) 혹은 graph를 그래프를 표현할 수 있는 자료구조형태로 변환하는 과정(위에서 말한 Adjacency matrix가 대표적)이 필요하다는 것이다.
Spectral vs Spacial
GNN의 방법론에는 크게 spatial 방법론과 spectral 방법론이 존재한다. 아래 그림을 보면 알 수 있듯이 초기에는 Spectral한 방법론들을 주로 사용하다. Spatial한 방법론으로 이동한 것을 알 수 있다.
아래 그림은 GNN의 방법론이 어떻게 변화했는지 도식화 한것으로, GCN 이후 Spatial한 방법론으로 paradaim shifting이 일어난것을 확인가능하다.
Spatial한 방법론은 주변부의 정보를 space관점으로 잘 모아서 target node의 정보를 업데이트하는 방법이다. 이전에 언급한 GCN과 같이, 주변 픽셀 대신에 연결된 점들의 특징을 잘 추출하여서 사용하는 것이다.

GNN의 흐름도, 출처: University of amsterdam Spectral한 방법의 경우 그래프의 신호 처리이론을 기반으로 고안된 방법으로, spectram을 기반으로 그래프를 분석하는 방법으로, 수학적인 기반을 매우 많이 가지고 있다.
"Spectral" simply means decomposing a signal/audio/image/graph into a combination (usually, a sum) of simple elements (wavelets, graphlets)
간단히 얘기하면 주어진 신호를 frequency domain 관점에서 요소의 합으로 분해하는 것으로, 대표적으로 푸리에 변환을 통해 우리가 주파수를 분해하는 것이 해당할 것이다.
그래프에서는 Laplacian matrix를 고유값 분해하는 것을 의미한다.
Laplacian matirx(라플라시안 행렬)

출처: https://en.wikipedia.org/wiki/Laplacian_matrix L, 라플라시안 행렬은 차수행렬에서 인접행렬을 뺀 것이다.
이렇게 값을 빼게 되면, Degree는 각 node에 몇개의 선이 연결되어있는가를 의미하고, Adjacency matrix 정보는 어떤 node에 연결되어있는지를 알려준다. 이때, 자기 자신에게 인접할 수는 없기에 이 둘을 빼게 되면 Degree정보를 대각원소에 Adjacency 정보는 비대각원소에 모두 담은 행렬(Laplacian matrix)을 만들 수 있다.
이후 이를 고유값 분해하여 그래프의 특성을 확인한다.
고유값 분해를 했을 때, 고유벡터의 경우 그래프의 연결성(topology)을 파악하는데 사용된다. Eigen value의 경우 그 값이 작은 경우는 local한 구조를 큰 vector는 그래프의 전반적인 구조적 특성을 나타낸다.
그럼 이러한 eigenvector들이 이루는 space에 signal을 투영해서( Graph Fourier Transform), eigen vector들에 관한 선형결합으로 표현하여. 해당 그래프가 어떻게 흩어지는지 확인 가능하다.
이때 signal이란 어떤 node의 특징이라고 할 수 있다.
즉, Sprectal 방법론은 그래프의 구조를 보존하면서 그래프의 위상과 그래프에서 어떤 feature들이 어떻게 분포되는지를 이해하여 전반적으로 유의미한 특성을 찾아내고자 하는 것이다.
Spectral 방법론: 그래프의 라플라시안 행렬을 찾아 고유값 분해하여 그래프의 latent 정보를 파악
Spatial 방법론: 인접한 정점의 정보를 고려하여 현재 정점의 정보를 업데이트하여 정점의 임베딩 학습GNN의 여러 종류
간단히 참고만 하면 좋을것 같다..! GraphSage등도 추가할 예정이다.
Recurrent Graph Neural Networks(RecGNNs)
GNN의 가장 시작이 된 모델로, 그래프 자체가 순환 구조이기에 recurrent한 모델로 이를 표현하고자 했다.
RecGNN은 노드를 RNN으로 학습하고자 하는 것에 중점을 둔다.
Convolutional Graph Neural Networks(ConvGNNs)
ConvGNN 은 convolution 이라는 연산을 그래프 데이터에 적용한 모델로. 핵심 아이디어는 특정 노드를 학습하기 위해 그 노드의 feature와 주변부 이웃노드의 feature를 aggregate하여 표현한 것이다.
ConvGNN은 여러 종류의 GNN 모델의 base로 많이 사용된다.
예를 들어, graph convolution 사이에 ReLU 를 두어 node classification 모델을 만들 수도 있고, convolution 을 계속 pooling 하여 softmax 를 적용하면 graph classification 모델이 된다.
Graph Autoencoders(GAEs)
GAE의 경우 문자 그대로 AutoEncoder를 이용한 모델로, 이 과정에서 모델의 latent vector를 얻는 모델이다. 이는 네트워크 임베딩(for latent node representation)과 graph genrative distribution(생성을 위한 확률분포)를 학습하기 위해 사용된다.
Spatial-temporal Graph Neural Networks(STGNNs)
Spatial-temporal(공간적-시간적) 그래프의 숨겨진 패턴들을 학습하기 위한 네트워크로, 공간적인 특성 뿐만 아니라 시간적인 의존성을 동시에 고려하는 모델이다. 현재 많은 접근 방식은 graph convolution을 통해 공간적인 특성을, RNN이나 CNN등을 이용해 시간적 특성을 고려하는 방식을 사용한다고 한다.
Graph Attention Network(GAT)
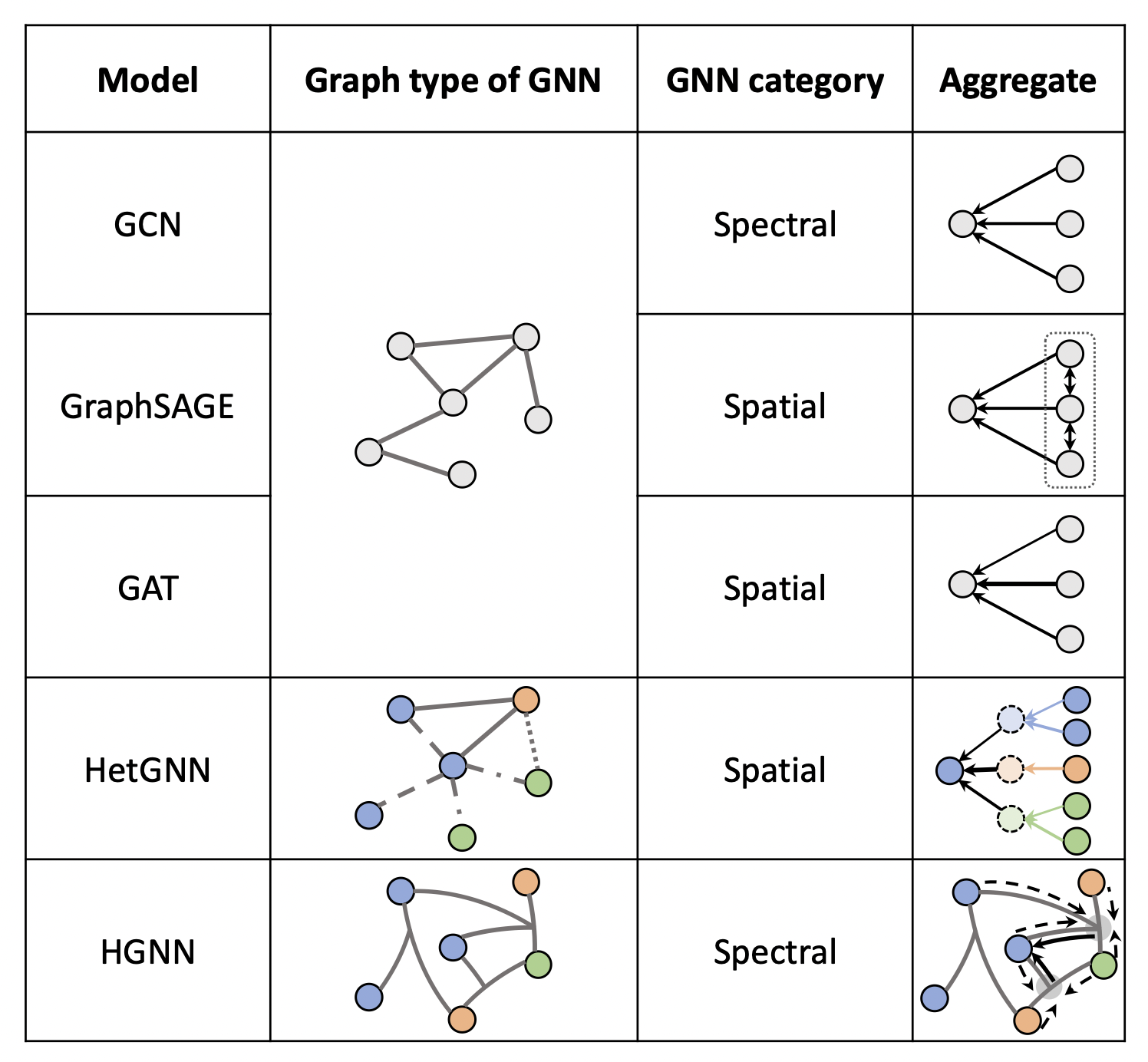
https://arxiv.org/pdf/2109.12843.pdf, Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions GAT는 Attention 기법을 이용한 모델로, GCN에서는 주변정점의 정보를 sum 하고, 전체 구조를 반영하기 위해 인접행렬을 이용한데 방면, GAT에서는 인접행렬을 사용하지 않고, 주변 정점의 정보를 가중합한다.
즉, Attention 기법과 같이 target정점에 가장 많은 영향력을 끼치는 node에 더 큰 가중(attention)을 부여하는 기법이다.
Neural Graph Collaborative Filtering(NGCF)
NGCF는 그래프가 가진 특징들을 이용해서 추천시스템에서 사용되는 유저-아이템 상호작용을 임베딩 레이어에서 추출하여 파라미터에 반영할 수 있도록 한 모델이다.
기존의 CF모델은 유저와 아이템의 임베딩을 학습한 이후에 이를 내적하는 방법으로(Matrix Factorization) 둘의 상호작용을 linear하게 표현한다. 이 과정에서 보통 유저-아이템 행렬은 매우 희소하다는 sparsity에 관한 문제나 cold start문제가 있었고. 더 복잡한 상호작용관계를 고려하지 못한다는 점이 한계였다.
반면 NGCF에서는 그래프 신경망을 통해 더 복잡한 형태의 상호작용등을 표현가능해졌다.

https://arxiv.org/pdf/1905.08108.pdf, Neural Graph Collaborative Filtering 조금더 자세히 말하면, NGCF는 유저와 아이템 간의 상호작용을 bi-graph로 만들고 이를 학습한다. 이때, 아이템의 개수가 많아질 수록 각 node가 모든 상호작용을 충분히 반영하지 못하기에. higher order connectivity를 통해 이를 조절하였다(어디까지 볼건지 range정해주기).
LightGCN
LightGCN이란 기존 GCN 모델을 경량화하여 핵심적인 부분만 사용하는 모델이다.
주변 이웃 노드로부터 메시지를 target 정점으로 전달할 때 가중치 파라미터를 곱하는 feature transformation 과정을 제거하고 단순히 normalized sum을 하는 과정으로 구현한 점.
Target node를 업데이트하는 과정에서 비선형성을 부여하기 위해 activation function을 사용한 GCN과 달리 이를 사용하지 않았다.
마지막으로 임베딩 벡터들을 concat하지 않고 가중합하는 과정으로 변경한 점이 차이다.
GNN은 어디에 사용되는가?
GNN이 해결하는 문제는 크게 3가지이다.
1. Node Classification
앞서 본 추천시스템에 해당하는 영역이다. 즉, 점들을 분류하는 문제다.
2. Link Prediction
이 또한 추천의 영역으로 볼 수 있으며, 그래프 간의 노드 간의 연결을 파악하고 두 노드 간 얼마나 연관성이 있을지를 예측하는(link를 만드는) 문제이다.
친구추천이나 관계도 분석 등이 있을 것이다.
3. Graph Classfication
그래프 전체를 어떤 카테고리에 속하는지 분류하는 문제이다. 대표적으로 화학의 분자구조를 분류하는 등의 문제가 있을 것이다.
이를 기반으로 Scence graph를 통한 물체간의 관계를 파악하거나, Visual Question Answering 등의 Vison쪽 분야나
Machine Learning for Scent: Learning Generalizable Perceptual Representations of Small Molecules 등과 같이 분자구조를 해석하는 데 사용하거나 Neural Graph Collaborative Filtering 처럼 추천에 사용하기도 한다.
'ML&DL 이야기 > ML' 카테고리의 다른 글
[Time-series] Long term time-series forecasting 연구동향 (0) 2024.04.06 [Time-series] Time-series Analysis, 시계열 알아보기 (2) 2024.03.22 [NLP processing] 자연어 데이터를 전처리해보자! (1) 2024.02.23 [NLP] BLEU Score(Bilingual Language Evaluation Understudy) (0) 2024.02.16 Beam Search in NLP (1) 2024.02.16