-
[Stat][검정] 순열 검정(Permutation test)Paper Review(논문이야기)/관련 개념 정리 2025. 3. 13. 20:12
비모수 검정 관련 방법들을 보다가 Below Permutation null ~, 이라는 말이 너무 많이 나와서 한번 정리해본다.
본 내용은 https://angeloyeo.github.io/2021/10/28/permutation_test.html 공돌이의 수학노트의 내용을 기반으로 작성되었습니다. 대부분의 그림자료 또한 해당 블로그의 자료임을 밝힙니다.
우선 Permutation test에 관해 알아보자.
Permutaion test
순열검정법(permuation test)은 두 개 이상의 표본을 함께 결합하여 관측값들을 무작위로 재표본으로 추출하고 이를 이용하여 가설 검정을 진행하는 방법을 말한다. 이때 재표본 추출(resampling)은 비복원 방식으로 진행한다....?
조금 더 알아보자.
두 그룹 간에 통계적으로 유의한 차이가 있는지 확인해보고 싶은 경우가 있다, t-test나 z-test 등이 있을 것이다. 다만, 이런 경우와 달리 우리가 어떤 분포를 따른다고 말하기 힘든 경우라면 어떠게 해야할까?
우리는 보통
두 표본 집단이 하나의 모집단에서 나왔다고 가정하자
라는 말을 흔히 통계문제를 풀때 보았을 것이다.
그 말은 아래와 같이 Group A와 Group B가 구분되어있더라도 동일한 모집단에서 왔다면 두 그룹 안에 있는 샘플을 교환한 뒤 검정통계량을 구해도 이전과 차이가 없어야할 것이다.


출처: https://angeloyeo.github.io/2021/10/28/permutation_test.html (공돌이의 수학노트 순열검정편) 즉 왼쪽과 같이 모든 표본이 동일한 모집단에서 왔다면 해당 샘플들을 교환한다고 해도 차이가 없을 것이지만, 오른쪽과 같은 경우라면 차이가 존재할 것이다(두 집단이 다들경우).
이것이 순열검정의 아이디어이다. 즉, 동일한 모집단이라면 그룹의 데이터가 섞인 뒤에 검정통계량을 구해도 똑같을 것이다! 라는 것이다.
조금 더 자세히 알아보자.
순열, 즉 데이터의 순서를 고려한 채 데이터셋을 뽑아보자.
아래의 예시를 생각해보자.
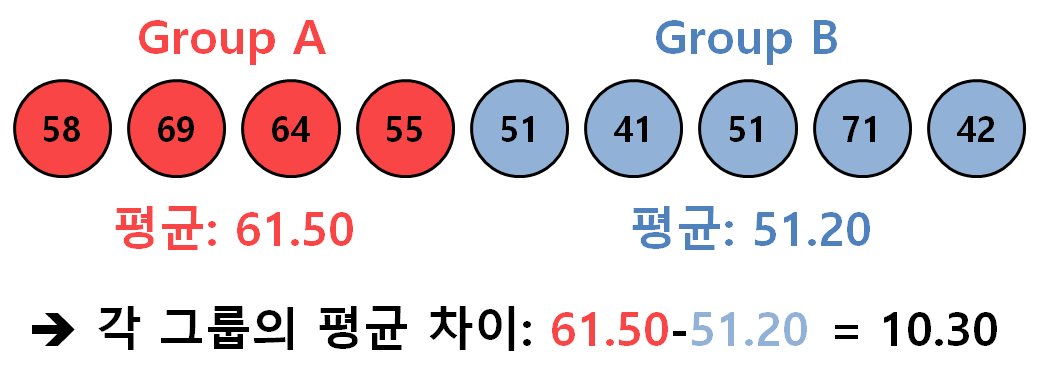
두 그룹의 평균의 차이(여기서 가정하는 검정통계량)는 과연 유의미한가? 를 알아보기 위해
각 그룹별 샘플들이 어떤 모집단에서 나왔는지 확인하기 어려운 상황 + 샘플의 수가 적은 상황(즉 CLT 사용이 어려움)이기에 순열검정을 사용해보자.
이를 위해 각 그룹의 데이터를 모두 합한 뒤 비복원 추출을 통해 데이터 셋을 새롭게 만들어보자.
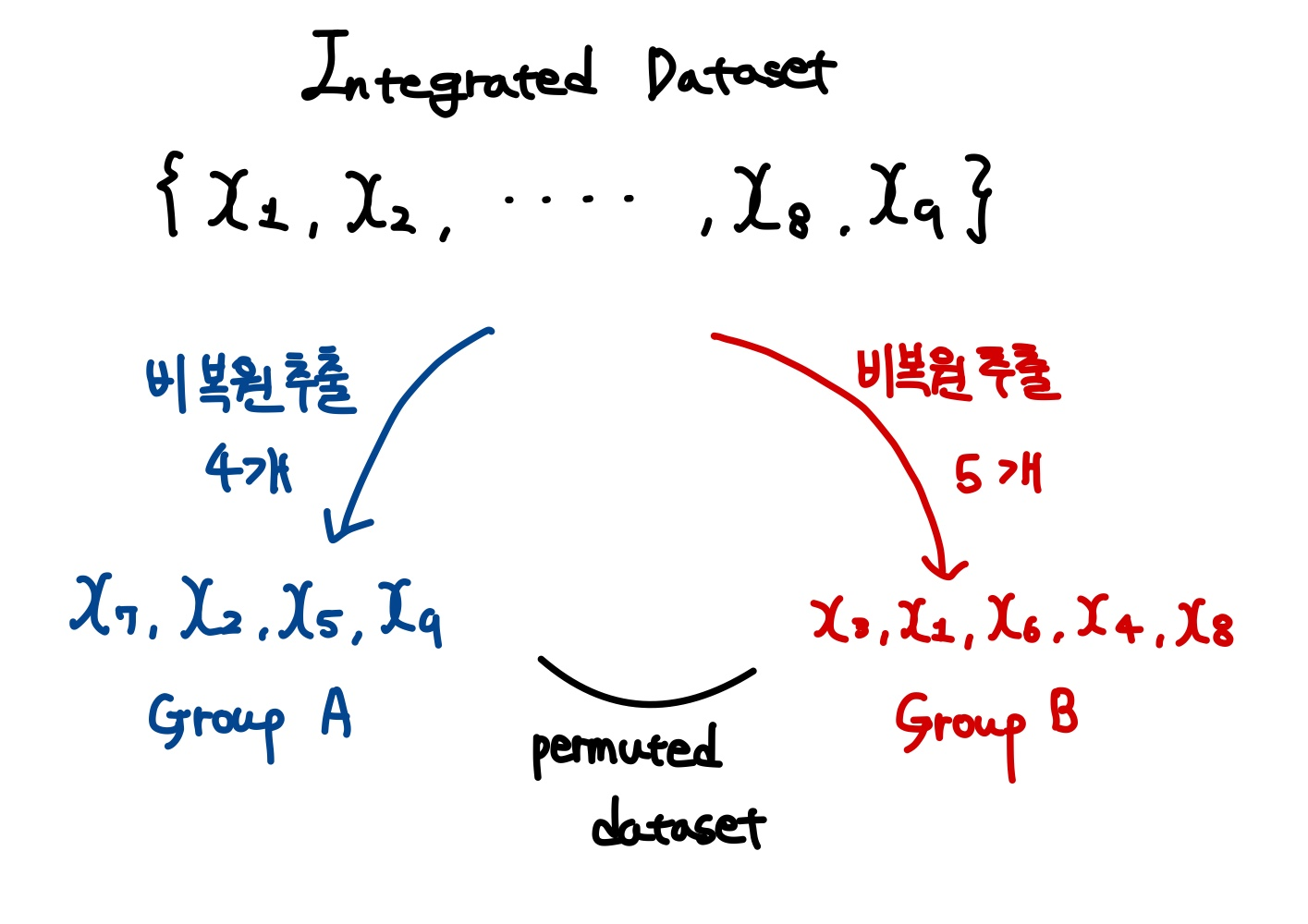
출처: https://esj205.oopy.io/0bf3f7b0-d3e0-4a0e-af64-d0b40a23b351 즉 위의 그림과 같은 상황일 것이다.
출처된 블로그에 따라 각 step을 반복하여 추출한다고 할 때 검정통계량을 보자.
1회차에서는 아래와 같았고,

2회차에서는 아래와 같은 값이 나왔다.

이를 꾸준히 반복하면서 n회차에 관해 값을 구하고 해당 값을 히스토그램의 표시해보자.
그러면 다음과 같은 분포를 얻을 수 있다.

그럼 우리는 이제 처음 주어진 10.3이라는 값이 permutation 분포에서 어디에 위치하고 있는지를 확인 가능하다.
즉 이제 emprical p-value를 구하고 significance level과 비교하여 가설을 검정할 수 있다.
p-value란 귀무가설이 참일 때, 관찰된 결과가 발생할 확률을 의미함 즉, p-value = P(x|H0)임
위의 정의에 따라서 p-value는 우리가
처음 구한 통계량보다 큰 경우의 수(or 작은 경우의 수)/ permuation으로 구한 통계량의 전체 개수
가 된다.
물론 양측이냐 단측이냐에 따라 다르다.
단측 검정인 경우, permuted test statistics가 observed test statistics보다 클 확률 또는 작을 확률을 구하고 양측 검정인 경우에는 permuted test statistics의 절댓값이 observed test statistics보다 클 확률을 구할 것이다.
영상에서는 p-value가 0.03이기에 상당히 분포의 끝에 위치함을 알 수 있고 해당 값이 유의수준보다 작으면 통계적으로 유의미하다고 할 수 있을 것이다.
'Paper Review(논문이야기) > 관련 개념 정리' 카테고리의 다른 글
[TIL] Confustion Matrix, ROC, AUC (0) 2025.03.15 [Kernel][미완] Reproducing Kernel Hilbert Space (RKHS) (0) 2025.03.14 [Time Series][Change point Detection] CUSUM method (0) 2025.02.09 [Time Series] Change point Detection (0) 2025.02.03