-
[TIL] Confustion Matrix, ROC, AUCPaper Review(논문이야기)/관련 개념 정리 2025. 3. 15. 20:28
Confusion Matrix란 claassfication 문제에 있어서 여러 지표를 알려주는 가장 근간이 되는 지표이다.
본 글에서는 binary classiifiication에 집중하여 내용을 작성한다.
본 자료는 KAIST 이종석 교수님의 제조인공지능 강의노트를 기반으로 작성되었고, 이미지 및 자료의 출처는 이를 따릅니다.
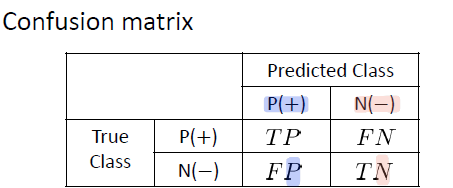
우선 다음을 가정하자. 우리는 기본적으로 postve class, 양성 샘플에 더 집중할 것이다. 이는 다음과 같다.
– Minority class (or positive(+) class): with fewer instances
– Majority class (or negative(−) class): with more instances예를 들면 베터리 제조 공정에서 불량품을 식별하는 것은 매우 중요한 문제이다. 이 경우 불량품이 + 양성이고, 정상품이 - 음성일것이다.
이제 Confusion Matrix를 기반으로 여러 개념들을 정리해보자.
Confustion Matrix
위에서 본 Matrix이다. 이 안에는
- TP (True Positive) : 예측을 positive로 했는데, 맞춘 경우
- TN (True Negative) : 예측을 negative로 했는데, 맞춘 경우
- FP (False Positive) : 예측을 positive로 했는데, 틀린경우
- FN (False Negative) : 예측을 negative로 했는데, 틀린경우
이게 사실 용어가 꽤나 햇갈리는데 다음과 같이 생각하면 쉽다.
우선 앞글자인 T, F는 맞았을 때 틀렸을 때임으로 쉽게 구분 가능하다. 문제는 뒤에 P냐 N이냐는것인데, 이는 내가 예측한 클래스를 따라간다. 즉 나의 예측이 뒷글자를 결정한다.
보면 내가 Postive로 예측해서 틀렸으면 False Postive이고, 내가 Neg로 예측해서 틀리면 FN이다! 쉽다!
그럼 이를 기반으로 각종 Metric을 정리해보자.
TPR vs FPR: 모델이 양성이라고 한것은 실제 양/음에서 얼마나 맞는가?

TPR: True Postive Rate, 실제 양성, True class에서 Postiive 중 모델이 양성으로 예측한 비율
FPR: False Postive Rate, 실제 음성, True class에서 Negative 중 모델이 양성으로 예측한 비율.
한마디로 모델은 양성으로 예측함 / 분모는 실제 양성인 것 아니면 아닌것을로 구분
Sensitivity vs Specificity: 실제 양/음에서 모델이 잘 맞춘것들은 얼마나 잘 맞췄을까

Sensitivity: 실제로 양성인 것 중 모델이 잘 맞춘 비율
Specificity: 실제로 음성인 것 중 음성이라고 잘 맞춘 비율
모델은 양성 음성을 각각 잘 맞출까?
Recall vs Precision: 모델이 TP를 얼마나 잘 맞추나

Recall:실제로 양성인 것 중 TP는 얼마나 잘 맞출까?
Precision: 모델이 양성이라고 한것 중 얼마나 실제 양성인가? -> 정밀도
Mean - measure

특정 지표 하나만 쓰지 않고, 여러개를 위에서 처럼 평균을 이용해서 반영가능하다.
이 중 AUC에 초점을 맞춰 알아보자.
ROC (Receiver Operating Characteristics)
ROC curve는 TPR을 Y축으로, FPR을 X축으로 둔 것이다(TPR은 실제 양성 중 TP, FPR은 실제 음성 중 FP(양성이라고 함)의 비율임을 잊지 말자)

ROC curve는 classifier가 얼마나 순서를 잘 맞히는지를 보여준다.
The ROC curve shows the ability of the classifier to rank the positive
instances relative to the negative instances.이게 무슨소리인가 알아보자.
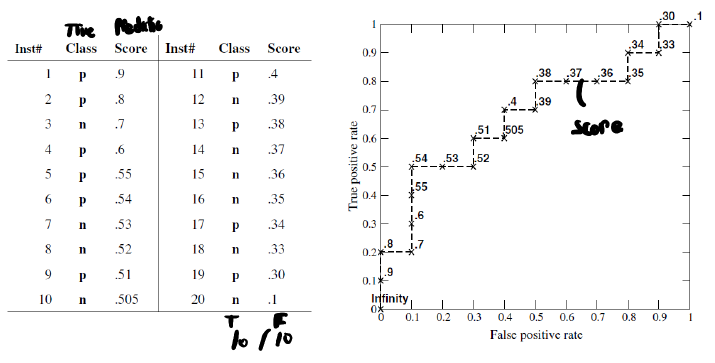
우선 표를 보면, 각 샘플 inst#에 관한 실제 Class가 명시되어있으며, Socre는 해당 샘플에 관한 어떤 임의의 모델의 점수라고 하자. 우리는 이제 특정 Threshold를 기준으로 P와 N를 나눌것이다.즉, 예측할 것이다.
이제 오른쪽 그래프를 보면 적힌 점선으로 표시되어있는 부분이 각 임계값이다.
임계값, τ에 따라 TPR과 FPR이 어떻게 바뀌는지 보자. instance는 20개이고, P와 N 각각 10개씩이다.
- τ > 0.9 : 모두 N이라고 예측할 것이다. 그럼 TPR: 0, FPR: 0이다.
- 0.9 >= τ > 0.8: Inst 1은 P 나머지는 N이라고 예측. 그럼 TPR: 0.1, FPR: 0이다.
이런식으로 각 Threshold에 대해 TPR과 FPR에 관해 점을 찍고 이을 수 있다.
두번째 예제를 보자. 이 예제는 순서를 제대로 지켰다. 즉 Score에 따라 True class가 정렬되어있음을 볼 수 있다.

즉, 만일 우리가 Treshold를 6과 7사이로 잡는다면 모델은 TPR이 1이고 FPR이 0인 모델이된다.
그렇기에 왼쪽의 그래프처럼 왼쪽에 딱 붙은 그래프가 나온다.
이것이 앞에서 말한 The ROC curve shows the ability of the classifier to rank the positive
instances relative to the negative instances. 의 의미이다. 즉, ranking을 잘 했는지 안했는지를 본다.
그럼 이제 우리는 좋은 ROC는 큰 AUC를 가진다는 것을 알았다.그러면 아래와 같은 AUC가 동일한 경우는 어떨까? 이럴 경우 높은 TPR, 즉 양성을 잘 골라내는 비율이 중요한것인지, 혹은 낮은 FPR, 음성 중에 양성이라고 한 비율이 낮은것(예시로 정상품을 불량품이라 할 비율이 낮은것)이 중요한지 선택하고 이에 따라 고르면 된다.
'Paper Review(논문이야기) > 관련 개념 정리' 카테고리의 다른 글
[Kernel][미완] Reproducing Kernel Hilbert Space (RKHS) (0) 2025.03.14 [Stat][검정] 순열 검정(Permutation test) (0) 2025.03.13 [Time Series][Change point Detection] CUSUM method (0) 2025.02.09 [Time Series] Change point Detection (0) 2025.02.03